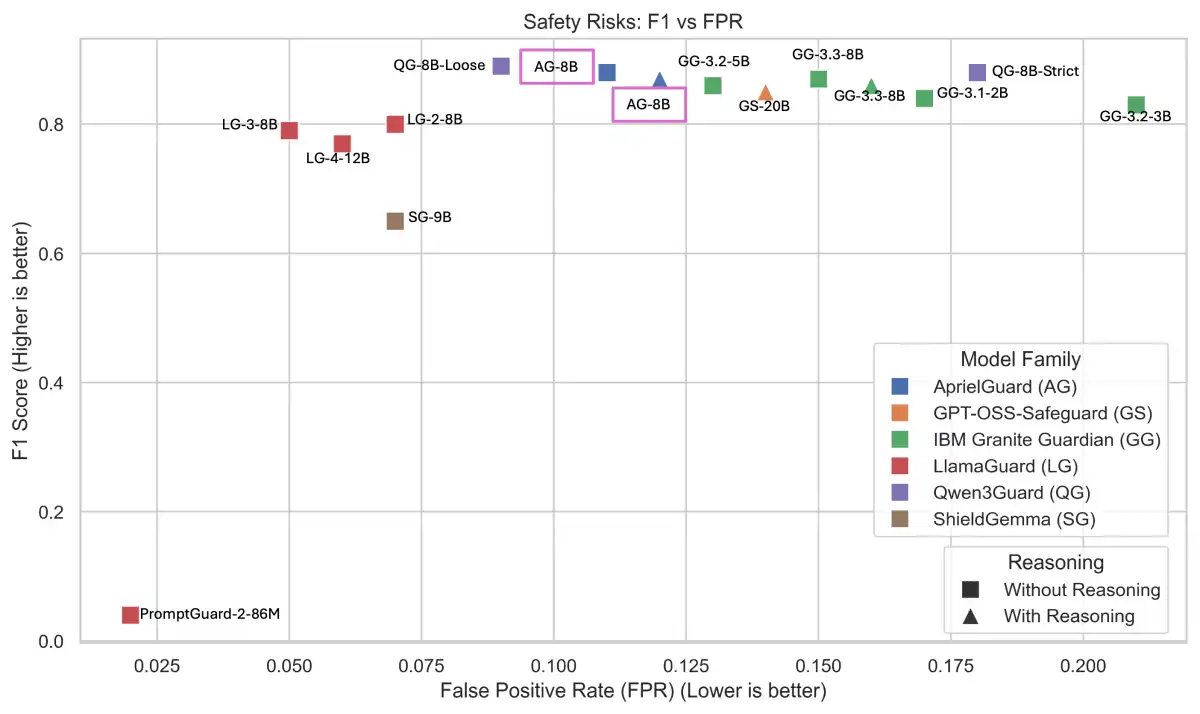
RapidFire AI has integrated its workflows with Hugging Face's Transformers Research Library (TRL), enabling users to fine-tune and post-train large language models (LLMs) up to 20 times faster. This integration allows for hyperparallelized execution, dynamic real-time experiment control, and automatic system optimization, making it easier for data scientists and ML engineers to customize LLMs and deep learning models.
What Happened
RapidFire AI's team has been working with Hugging Face TRL lead maintainer Quentin Gallouédec to build workflows on top of the library. The result is an official integration that enables users to run multiple configurations in parallel, compare them concurrently, and dynamically prune or clone promising runs. This accelerates discovery within the same time frame as traditional sequential processing.
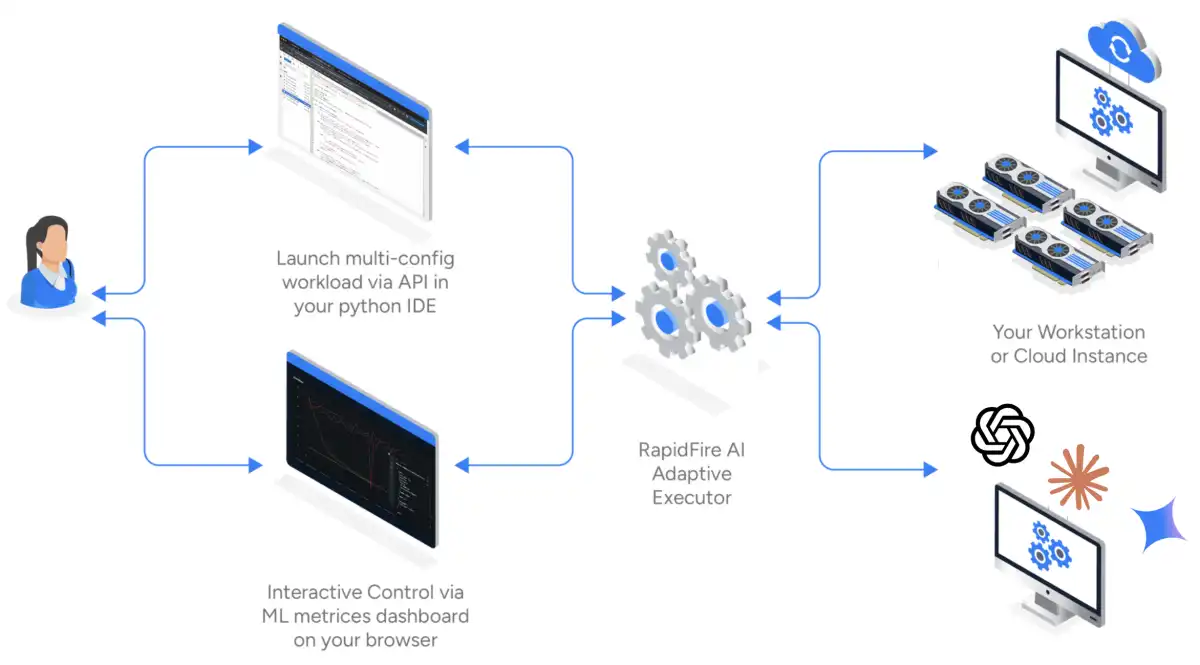
The integration includes drop-in TRL wrappers for SFT, DPO, and GRPO configs, adaptive chunk-based concurrent training, interactive control operations (IC Ops), multi-GPU orchestration, and an MLflow-based dashboard for real-time metrics and logs. This allows users to launch multiple configurations simultaneously, explore variations of prompt schemes, chunking, retrieval, reranking, and generation even on a single GPU or CPU-only machine.
Background and Context
RapidFire AI is an open-source framework that makes LLM customization faster, more systematic, and more impactful. The company's mission is to bridge the gap between research and practical AI applications across various domains. RapidFire AI's co-founder and CTO Arun Kumar explained in an interview with Pulse 2.0 that the idea for the company came from their own experiences with AI applications in both domain sciences and industry.
Kumar shared that they saw how time-consuming and complex it was to experiment with deep learning models, even small tweaks taking weeks to test. This led them to create a system that makes AI experimentation much faster, more flexible, and scalable so that AI teams can iterate quickly and get better results without being bottlenecked by infrastructure.
Why It Matters to the Industry
This integration has significant implications for the adult industry, where LLM customization is crucial for applications such as chatbots, content generation, and moderation. The ability to fine-tune and post-train models up to 20 times faster will enable developers to experiment with more configurations, explore new ideas, and improve model performance.
The integration's hyperparallelized execution and dynamic real-time control features will also help reduce the time and resources required for experimentation, making it easier for developers to iterate quickly and respond to changing market demands. Additionally, the automatic system optimization feature will ensure that resources are utilized efficiently, reducing waste and costs associated with infrastructure.
What Comes Next
RapidFire AI is encouraging users to try the integration and share their experiences. The company's co-founder and CTO Arun Kumar invites feedback from the community, stating that it will shape where they go from here. Users can get started quickly by installing RapidFire AI via PyPI and following the instructions on the GitHub repository.
Key Facts
- RapidFire AI has integrated its workflows with Hugging Face's Transformers Research Library (TRL).
- The integration enables users to fine-tune and post-train LLMs up to 20 times faster.
- The integration includes drop-in TRL wrappers for SFT, DPO, and GRPO configs.
- Users can launch multiple configurations simultaneously, exploring variations of prompt schemes, chunking, retrieval, reranking, and generation even on a single GPU or CPU-only machine.
- The integration includes adaptive chunk-based concurrent training, interactive control operations (IC Ops), multi-GPU orchestration, and an MLflow-based dashboard for real-time metrics and logs.
- RapidFire AI is encouraging users to try the integration and share their experiences.