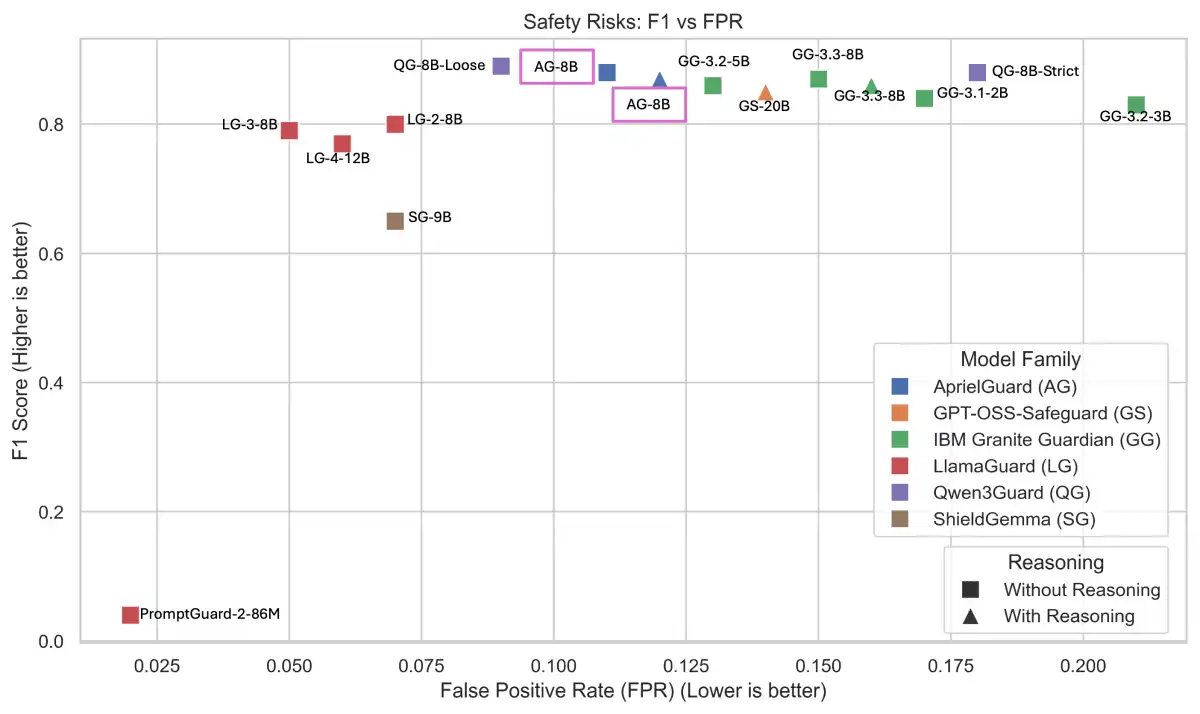
A new safeguard model has been introduced to protect large language models (LLMs) from unsafe or adversarial behavior. AprielGuard, an 8B-parameter model developed by ServiceNow AI, unifies safety risks and adversarial threats within a single taxonomy and learning framework.
Background and Context
The increasing complexity of LLMs has led to a growing need for comprehensive safety guardrails. As these models evolve from static conversational systems into autonomous, goal-driven agents capable of planning, decision-making, and executing tasks through external tools and APIs, the risk of safety breaches and adversarial attacks also increases.
Traditional moderation and safety systems are often designed primarily for short-form, single-turn interactions and are ill-equipped to detect or mitigate emerging threat patterns. Existing moderation tools often treat safety risks (e.g., toxicity, bias) and adversarial threats (e.g., prompt injections, jailbreaks) as separate problems, limiting their robustness and generalizability.
What Makes AprielGuard Different
AprielGuard addresses these limitations by introducing a unified taxonomy that covers 16 distinct safety categories alongside a robust adversarial attack detection system. The model is trained on a diverse mix of open and synthetic data covering standalone prompts, multi-turn conversations, and agentic workflows, augmented with structured reasoning traces to improve interpretability.
The 16 safety categories are inspired by the SALAD-Bench framework and include "Toxic Content," "Unfair Representation," and "Violation of Personal Property," among others. The model also addresses a spectrum of adversarial strategies, including code encodings, prompt injections, stylizing, rhetorical manipulation, and role-playing.
Why It Matters to the Industry
The introduction of AprielGuard is significant for the adult industry, which relies heavily on LLMs for content moderation, age verification, and payment processing. The model's ability to detect safety risks and adversarial threats in complex workflows makes it an essential tool for protecting against emerging threat patterns.
AprielGuard's unified taxonomy and robust adversarial attack detection system enable more effective safeguarding of LLMs in diverse conversational and agentic settings. This is particularly important for the adult industry, where the consequences of safety breaches and adversarial attacks can be severe.
What Comes Next
The release of AprielGuard marks a significant step forward in the development of comprehensive safety guardrails for LLMs. As the model continues to evolve, it is likely that we will see increased adoption across various industries, including the adult industry.
The authors of AprielGuard aim to advance transparent and reproducible research on reliable safeguards for LLMs by releasing the model. This openness and collaboration are essential for driving innovation and improving safety in the development of AI-powered systems.
Key Facts
- AprielGuard is an 8B-parameter model developed by ServiceNow AI to address safety risks and adversarial threats in LLMs.
- The model unifies safety risks and adversarial threats within a single taxonomy and learning framework.
- AprielGuard is trained on a diverse mix of open and synthetic data covering standalone prompts, multi-turn conversations, and agentic workflows.
- The model addresses a spectrum of adversarial strategies, including code encodings, prompt injections, stylizing, rhetorical manipulation, and role-playing.
- AprielGuard has been shown to achieve strong performance in detecting harmful content and adversarial manipulations across multiple public and proprietary benchmarks.