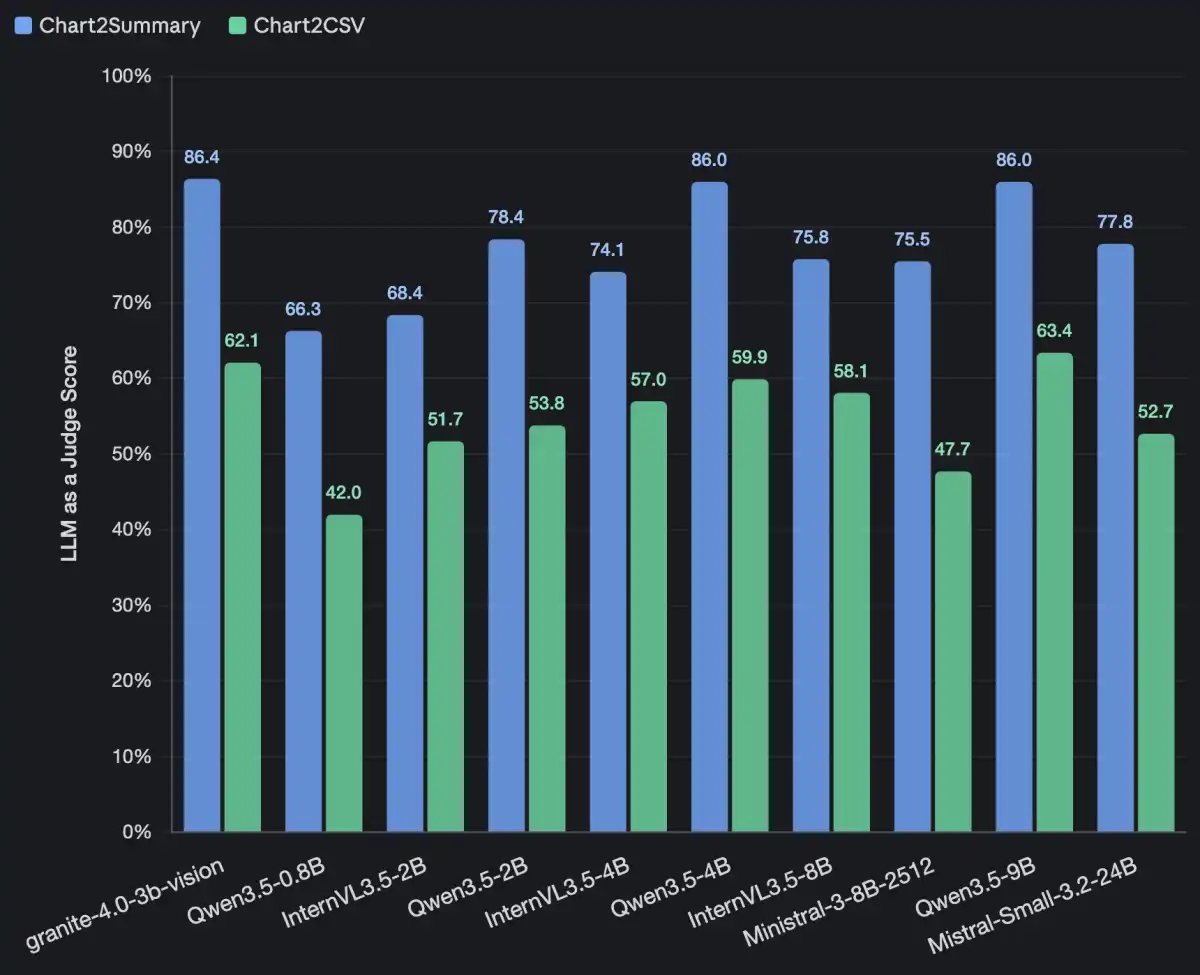
The Technology Innovation Institute (TII) has announced Falcon Perception, a unified dense Transformer model that combines vision and language capabilities to enable systems to see, read, and understand images using natural language prompts. This innovative architecture processes images, embedded text, and visual context in one stream, allowing organisations to extract structured information from complex visual data with fewer systems and greater consistency.
Falcon Perception is a significant development in the field of computer vision and natural language processing, as it challenges the traditional approach of using multiple specialized models for object detection, text recognition, and scene interpretation. The model's unified architecture enables it to perform a range of tasks, including object detection, instance segmentation, and OCR (Optical Character Recognition), all from a single input.
Background and Context
The development of Falcon Perception is the result of ongoing research in the field of multimodal AI. The TII's Falcon LLM family has been designed to expand the possibilities of generative AI across industries and disciplines, with a focus on efficiency, ethical design, and global scalability. Falcon Perception is part of this effort, aiming to make advanced AI accessible and impactful.
The model's architecture is based on a dense Transformer that processes image patches and text tokens in a shared parameter space from the first layer. This approach allows for early fusion of visual and linguistic information, enabling the model to perform tasks such as object detection and instance segmentation with high accuracy. The model also uses a hybrid attention pattern, which combines bidirectional attention among image tokens with causal attention for prediction tokens.
Why it Matters to the Industry
Falcon Perception has significant implications for industries that rely heavily on visual data, such as adult content platforms. The ability to extract structured information from complex visual data using natural language prompts could revolutionize the way these platforms operate. For example, Falcon Perception could be used to automate tasks such as image tagging, categorization, and moderation, freeing up human moderators to focus on more complex tasks.
The model's unified architecture also makes it an attractive solution for industries that require high levels of consistency and accuracy in their visual data processing tasks. By reducing the need for multiple specialized models, Falcon Perception could help organizations streamline their workflows and improve their overall efficiency.
What Comes Next
The TII has made Falcon Perception available as an open-source model, allowing researchers and developers to build upon its architecture and explore new applications. The model's performance on a range of tasks, including object detection and instance segmentation, is impressive, with results showing that it outperforms state-of-the-art models in many cases.
The TII has also announced plans to release Falcon OCR, a compact 300M-parameter model that attains 80.3% on olmOCR and 88.64 on OmniDocBench. This model is designed for text extraction tasks and could have significant implications for industries that rely heavily on text data.
Key Facts
- Falcon Perception is a unified dense Transformer model that combines vision and language capabilities to enable systems to see, read, and understand images using natural language prompts.
- The model's architecture processes images, embedded text, and visual context in one stream, allowing organisations to extract structured information from complex visual data with fewer systems and greater consistency.
- Falcon Perception outperforms state-of-the-art models on a range of tasks, including object detection and instance segmentation.
- The TII has made Falcon Perception available as an open-source model, allowing researchers and developers to build upon its architecture and explore new applications.
- Falcon OCR is a compact 300M-parameter model that attains 80.3% on olmOCR and 88.64 on OmniDocBench, designed for text extraction tasks.