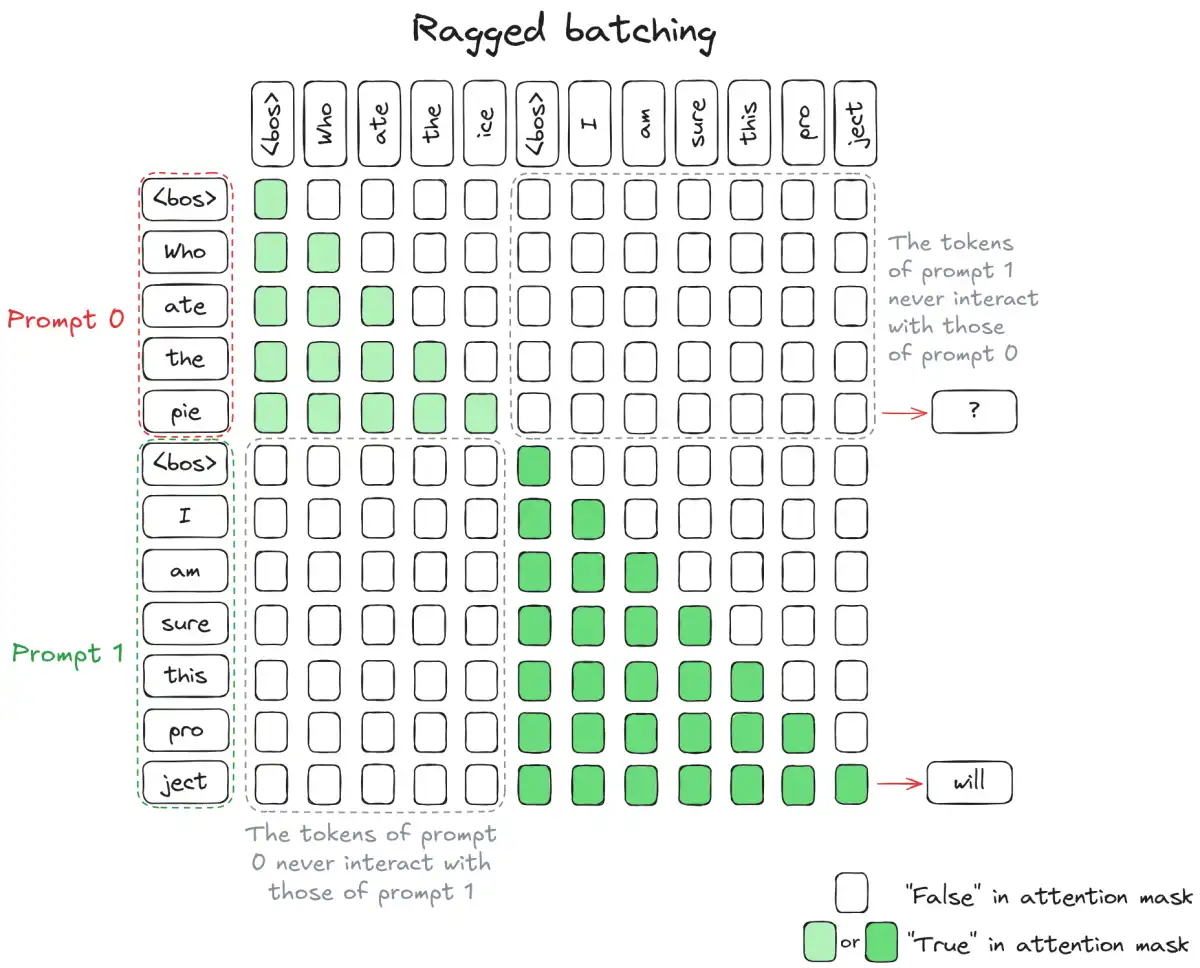
The latest breakthrough in large language model (LLM) inference throughput has been achieved through a technique called continuous batching. This innovative approach has been shown to increase throughput by 2-3x compared to traditional static batching methods, making it a game-changer for the industry.
**What Happened**
Continuous batching was first introduced as a solution to the inefficiencies of traditional static batching in LLM inference. Static batching collects a set of requests and processes them as a unit through the model until every sequence has finished generating, then moves on to the next batch. However, this approach falls apart when dealing with output length variance, where some requests may complete quickly while others take much longer.
**Background and Context**
LLM inference requires tight collaboration between CPUs and GPUs. While the major computation happens in GPUs, CPUs also play a crucial role in serving and scheduling requests. If CPUs cannot schedule fast enough, GPUs will sit idle waiting for CPUs, leading to inefficient GPU utilization and hindering inference performance. In traditional batching, the entire batch is held hostage by its slowest member, wasting power and causing inflexible workflows.
**Why it Matters**
Continuous batching solves these problems by moving the scheduling decision from the request granularity to the iteration granularity. The scheduler runs once per model forward pass, not once per request. When a sequence emits an end-of-sequence token and finishes, its memory slot is freed immediately. The next waiting request is inserted into the batch before the next iteration begins. This approach eliminates wasted power and inflexible workflows, making it a significant improvement over traditional static batching.
**What Comes Next**
The implications of continuous batching are far-reaching, with potential applications in various industries such as customer service, content creation, and more. As the demand for LLM inference continues to grow, continuous batching is poised to become an essential component of any high-performance LLM serving infrastructure.
**Key Facts**
- Continuous batching increases throughput by 2-3x compared to traditional static batching methods.
- This approach eliminates wasted power and inflexible workflows in LLM inference.
- The scheduler runs once per model forward pass, not once per request.
- When a sequence finishes, its memory slot is freed immediately, allowing the next waiting request to be inserted into the batch.
- Continuous batching has been shown to improve throughput by 2-3x compared to traditional static batching methods.
**Conclusion**
Continuous batching is a revolutionary technique that has the potential to transform the LLM inference industry. By eliminating wasted power and inflexible workflows, this approach offers significant improvements in throughput and efficiency. As the demand for LLM inference continues to grow, continuous batching is poised to become an essential component of any high-performance LLM serving infrastructure.