The shift from a single pre-training scaling law to three complementary regimes—pre-training, post-training, and test-time compute—has not fragmented infrastructure requirements; it has reinforced them. All three regimes demand tightly coupled accelerator compute, high-bandwidth low-latency networking, and scalable distributed storage, differing mainly in workload profile and resource scheduling patterns.
Building Blocks for Foundation Model Training and Inference on AWS
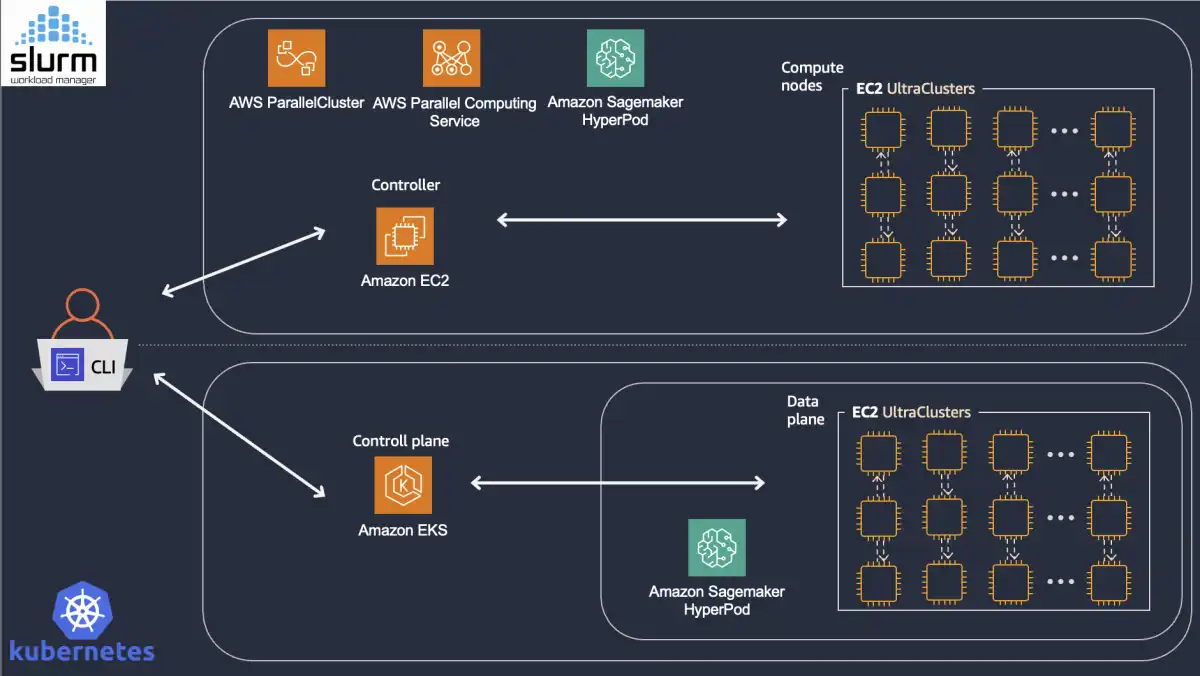
The four-layer architecture that addresses those requirements on AWS includes infrastructure building blocks (EC2 P-instances, EFA networking, and tiered storage), resource orchestration (Slurm and Kubernetes with SageMaker HyperPod), the ML software stack (from kernel drivers and CUDA through NCCL to PyTorch), and observability (Prometheus, Grafana, and GPU health monitoring). Each layer constrains and enables the layers above it—a misconfigured driver or saturated network link can bottleneck an otherwise well-tuned training run just as effectively as a suboptimal parallelism strategy.
Understanding these integration points is the foundation for diagnosing performance bottlenecks and making informed scaling decisions across the foundation model lifecycle. Aman Shanbhag, AI Performance and Infrastructure Engineer on the MARS MLOps team at NVIDIA, Pavel Belevich, Senior Applied Scientist in the GenAI ML Frameworks team at Amazon Web Services, and Keita Watanabe, Principal Solutions Architect in the GenAI ML Frameworks team at AWS, have contributed to this article.
Powering Innovation at Scale: How AWS is Tackling AI Infrastructure Challenges
As generative AI continues to transform how enterprises operate—and develop net new innovations—the infrastructure demands for training and deploying AI models have grown exponentially. Traditional infrastructure approaches are struggling to keep pace with today’s computational requirements, network demands, and resilience needs of modern AI workloads.
At AWS, we’re also seeing a transformation across the technology landscape as organizations move from experimental AI projects to production deployments at scale. This shift demands infrastructure that can deliver unprecedented performance while maintaining security, reliability, and cost-effectiveness. That’s why we’ve made significant investments in networking innovations, specialized compute resources, and resilient infrastructure that’s designed specifically for AI workloads.
Layer 2: Approved Set of Foundation Models and Tools
As organizations navigate the early stages of generative AI adoption, they quickly realize that no single model can address all use cases effectively. Different models excel in various domains and tasks, and enterprises need to balance capability, cost, and performance for each specific application. This reality drives the need for a flexible, yet controlled, approach to foundation model access.
Amazon Bedrock is designed to help you experiment with various foundation models, and it supports scalable production deployments. With Amazon Bedrock Knowledge Bases, you have a fully managed solution to build end-to-end Retrieval Augmented Generation (RAG) workflows. Amazon Bedrock also supports managed agents that can run complex tasks without code, from booking travel to managing inventory.
Getting Started with AWS Foundational Models
Foundation models are large-scale AI models pretrained on massive datasets. They are versatile across different applications with minimal task-specific training. Think of them as a Swiss army knife for AI—capable of handling text, images, and code with minimal customization.
Unlike traditional machine learning models, which require task-specific training from scratch, foundation models provide a strong base that can be fine-tuned for specific applications like chatbots, content creation, and code generation. This adaptability makes them highly efficient for real-world AI solutions.
Key Facts
- Foundation models are large-scale AI models pretrained on massive datasets.
- The four-layer architecture that addresses infrastructure requirements on AWS includes infrastructure building blocks, resource orchestration, the ML software stack, and observability.
- AWS has made significant investments in networking innovations, specialized compute resources, and resilient infrastructure designed specifically for AI workloads.
- Amazon Bedrock is a fully managed solution to build end-to-end Retrieval Augmented Generation (RAG) workflows.
- Foundation models provide a strong base that can be fine-tuned for specific applications like chatbots, content creation, and code generation.
The shift from a single pre-training scaling law to three complementary regimes—pre-training, post-training, and test-time compute—has not fragmented infrastructure requirements; it has reinforced them. All three regimes demand tightly coupled accelerator compute, high-bandwidth low-latency networking, and scalable distributed storage, differing mainly in workload profile and resource scheduling patterns.