The adult industry's reliance on large language models (LLMs) for chatbots and other applications has led to a pressing need for efficient inference techniques. A recent development in this area is continuous batching, a technique that maximizes performance by processing multiple conversations in parallel and swapping them out when they are done.
Background and Context
LLMs are complex neural networks that process text by breaking it down into tokens. Each token is represented as a vector of dimension d, and the attention mechanism allows different tokens to interact with each other. However, this interaction comes at a cost: computing the attention scores requires O(n^2d) operations, where n is the sequence length.
To make LLMs practical for real-world applications, researchers and engineers have developed various efficient inference techniques. One of these techniques is continuous batching, which attempts to maximize performance by processing multiple conversations in parallel and swapping them out when they are done.
How Continuous Batching Works
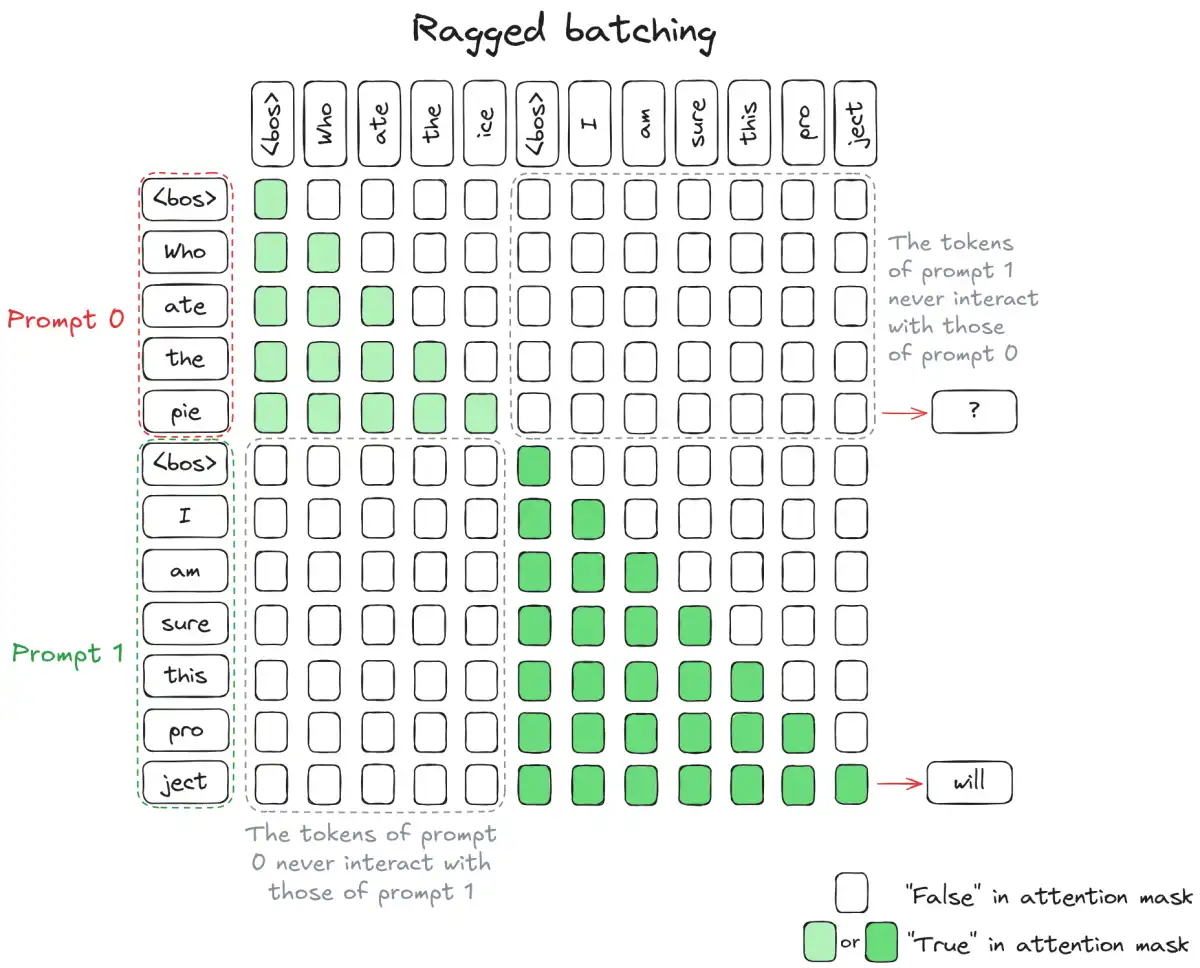
The key insight behind continuous batching is that the attention mechanism can be optimized for throughput by using a technique called ragged batching. In traditional batched generation, all prompts must have the same length, which requires padding to ensure that all tokens are processed in parallel. However, this approach leads to wasted compute and memory.
Ragged batching, on the other hand, allows sequences of different lengths to be batched together by categorizing operations into two groups: those that are compatible with different-length sequences (such as matrix multiplication) and those that are not (such as attention layers). By processing the first group in a batched manner and splitting the second group by request, ragged batching enables efficient handling of sequences of varying lengths.
Why It Matters to the Industry
The adult industry relies heavily on LLMs for chatbots and other applications. However, these models require significant computational resources to process large amounts of text data. Continuous batching offers a solution to this problem by maximizing performance while minimizing waste.
According to AI21, continuous batching is the primary mechanism for achieving high throughput in online LLM inference serving, particularly under variable or bursty request patterns. By treating each forward pass through the model as an opportunity to update the batch composition, continuous batching eliminates the padding problem and allows new requests to join an active generation batch as soon as a slot becomes available.
What Comes Next
The development of continuous batching is an important step towards making LLMs more efficient and practical for real-world applications. However, there are still challenges to be addressed in this area. For example, configuring continuous batching correctly requires matching the maximum number of sequences and batched tokens to the actual workload characteristics.
Key Facts
- Continuous batching is a technique that maximizes performance by processing multiple conversations in parallel and swapping them out when they are done.
- Ragged batching allows sequences of different lengths to be batched together by categorizing operations into two groups: those that are compatible with different-length sequences and those that are not.
- Continuous batching eliminates the padding problem and allows new requests to join an active generation batch as soon as a slot becomes available.
- The primary mechanism for achieving high throughput in online LLM inference serving is continuous batching, particularly under variable or bursty request patterns.
- Configuring continuous batching correctly requires matching the maximum number of sequences and batched tokens to the actual workload characteristics.
In conclusion, continuous batching is a significant development in the field of efficient inference techniques for LLMs. By maximizing performance while minimizing waste, this technique has the potential to revolutionize the way we use these models in real-world applications.