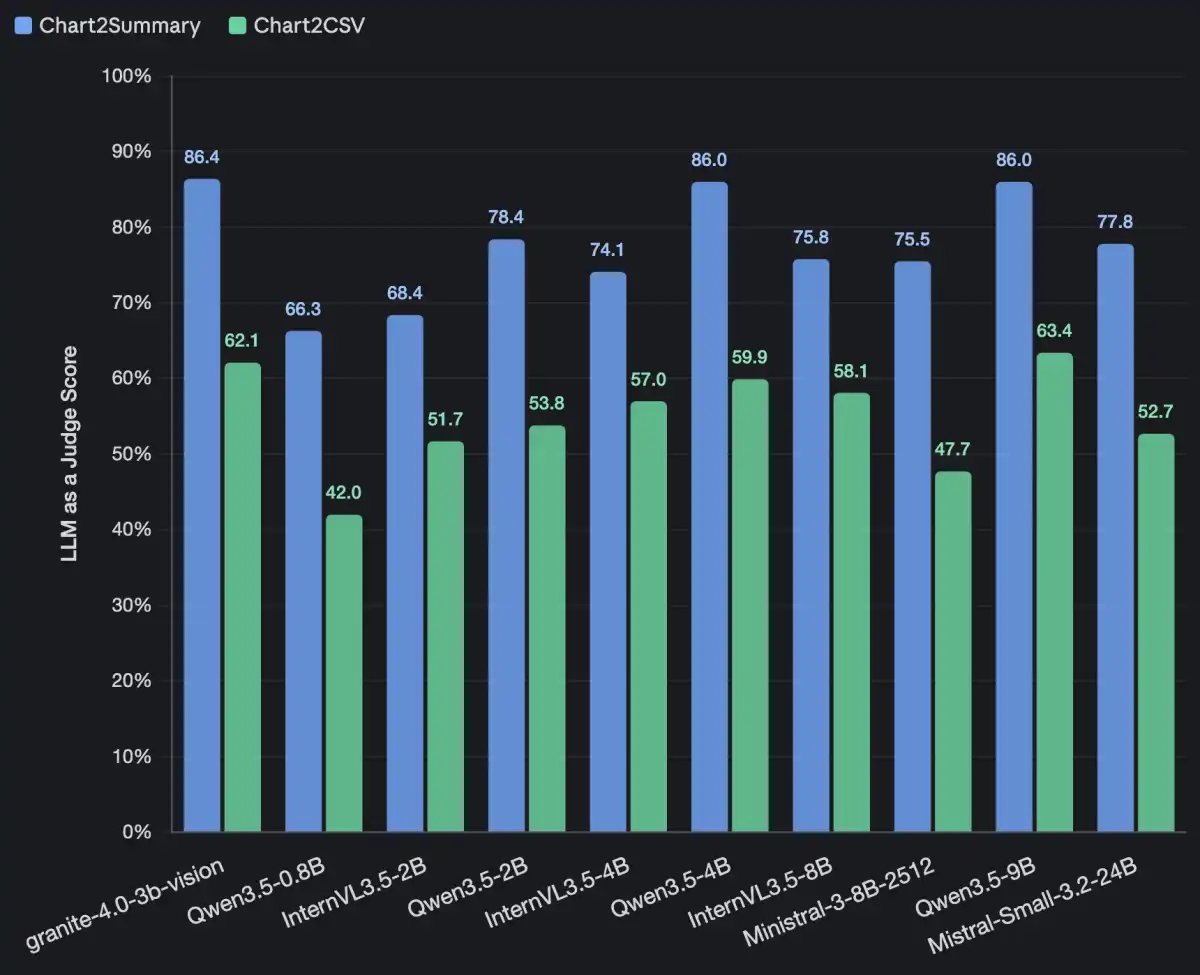
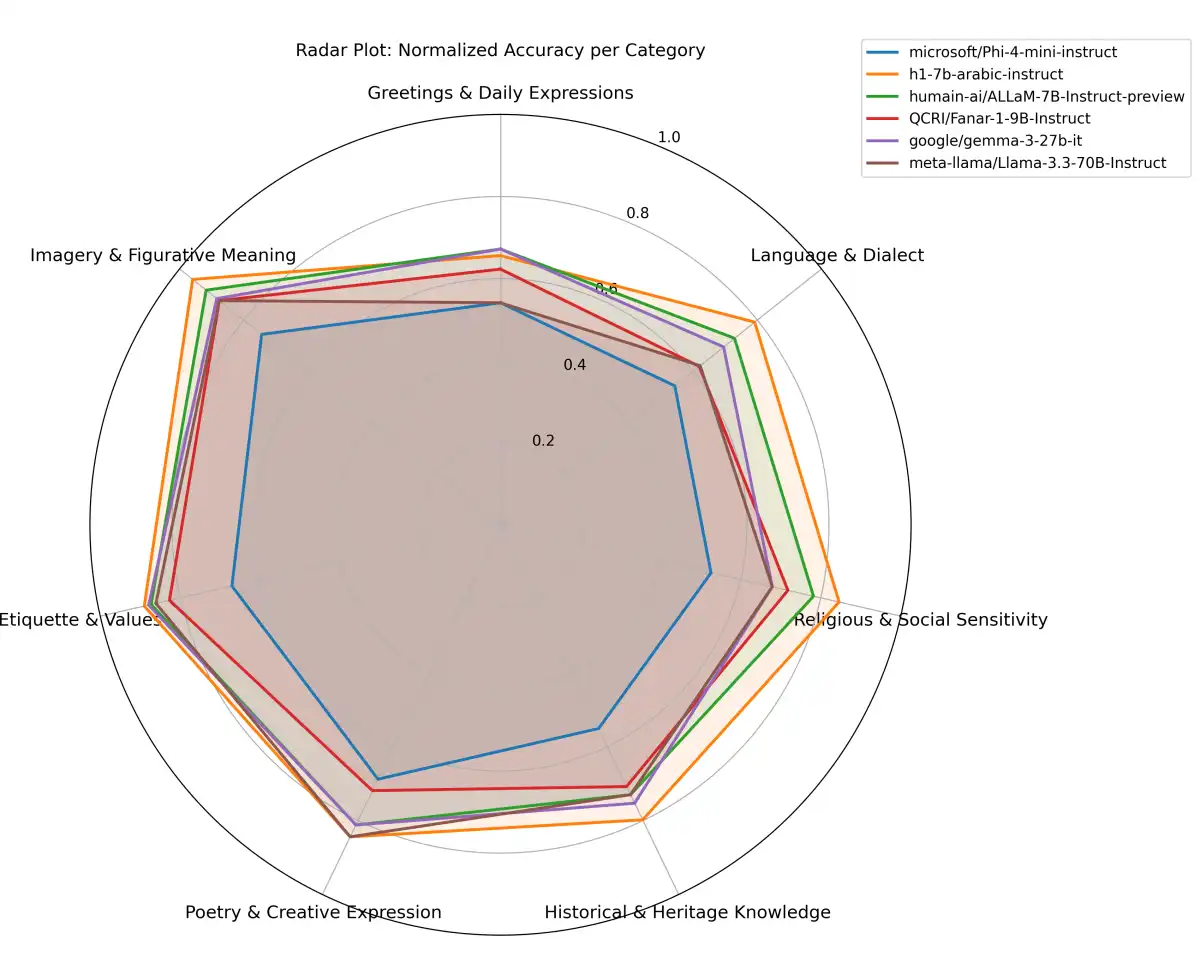
The IBM Research team has introduced VAKRA, a tool-grounded, executable benchmark designed to evaluate how well AI agents reason end-to-end in enterprise-like settings. The benchmark measures compositional reasoning across APIs and documents, using full execution traces to assess whether agents can reliably complete multi-step workflows.
What Happened
VAKRA is a tool-grounded, executable benchmark designed to evaluate how well AI agents reason end-to-end in enterprise-like settings. The benchmark measures compositional reasoning across APIs and documents, using full execution traces to assess whether agents can reliably complete multi-step workflows. Unlike traditional benchmarks that test isolated skills, VAKRA evaluates how well agents can chain decisions across systems, reconcile mismatched schemas, interpret tool constraints expressed in natural language, ground answers in retrieved evidence, and reuse intermediate outputs to parameterize later tool calls.
The benchmark provides an executable environment where agents interact with over 8,000 locally hosted APIs backed by real databases spanning 62 domains, along with domain-aligned document collections. Tasks can require 3-7 step reasoning chains that combine structured API interaction with unstructured retrieval under natural-language tool-use constraints. Locally hosted, database-backed tools ensure deterministic, verifiable responses at evaluation.
Background and Context
The IBM Research team has been working on developing a benchmark to evaluate the performance of AI agents in complex, multi-step tasks. The goal is to create a benchmark that can assess an agent's ability to reason end-to-end in enterprise-like settings, where workflows often involve chaining decisions across systems, reconciling mismatched schemas, and following tool-use policies expressed in natural language.
The team has been inspired by the limitations of traditional benchmarks, which often focus on isolated skills such as single-turn QA or one-off function calls. In practice, agents must be able to perform complex tasks that involve multiple steps, tools, and data sources. VAKRA is designed to surface exactly where multi-step reasoning succeeds or breaks down, reflecting the realities agents face in production environments.
Why it Matters
VAKRA matters because it provides a comprehensive evaluation framework for AI agents in complex, multi-step tasks. The benchmark can help developers and researchers identify areas where their agents are struggling to reason end-to-end, and provide insights into how to improve performance. In the adult industry, this is particularly relevant as many platforms rely on AI-powered tools to manage workflows, moderate content, and ensure compliance with regulations.
The IBM Research team has highlighted several key challenges that VAKRA addresses, including entity disambiguation, cross-source grounding, parameter and schema alignment, tool selection under interface variation, and policy interpretation during execution. These challenges are particularly relevant in the adult industry, where agents must be able to navigate complex workflows, reconcile mismatched schemas, and follow tool-use policies expressed in natural language.
What Comes Next
The IBM Research team has made VAKRA available as an open-source benchmark, allowing developers and researchers to run their own agents on the platform. The team is also encouraging submissions to the leaderboard, where participants can compare their agent's performance with others in the community.
Key Facts
- VAKRA is a tool-grounded, executable benchmark designed to evaluate how well AI agents reason end-to-end in enterprise-like settings.
- The benchmark measures compositional reasoning across APIs and documents, using full execution traces to assess whether agents can reliably complete multi-step workflows.
- VAKRA provides an executable environment where agents interact with over 8,000 locally hosted APIs backed by real databases spanning 62 domains.
- Tasks in VAKRA can require 3-7 step reasoning chains that combine structured API interaction with unstructured retrieval under natural-language tool-use constraints.
- VAKRA is designed to surface exactly where multi-step reasoning succeeds or breaks down, reflecting the realities agents face in production environments.