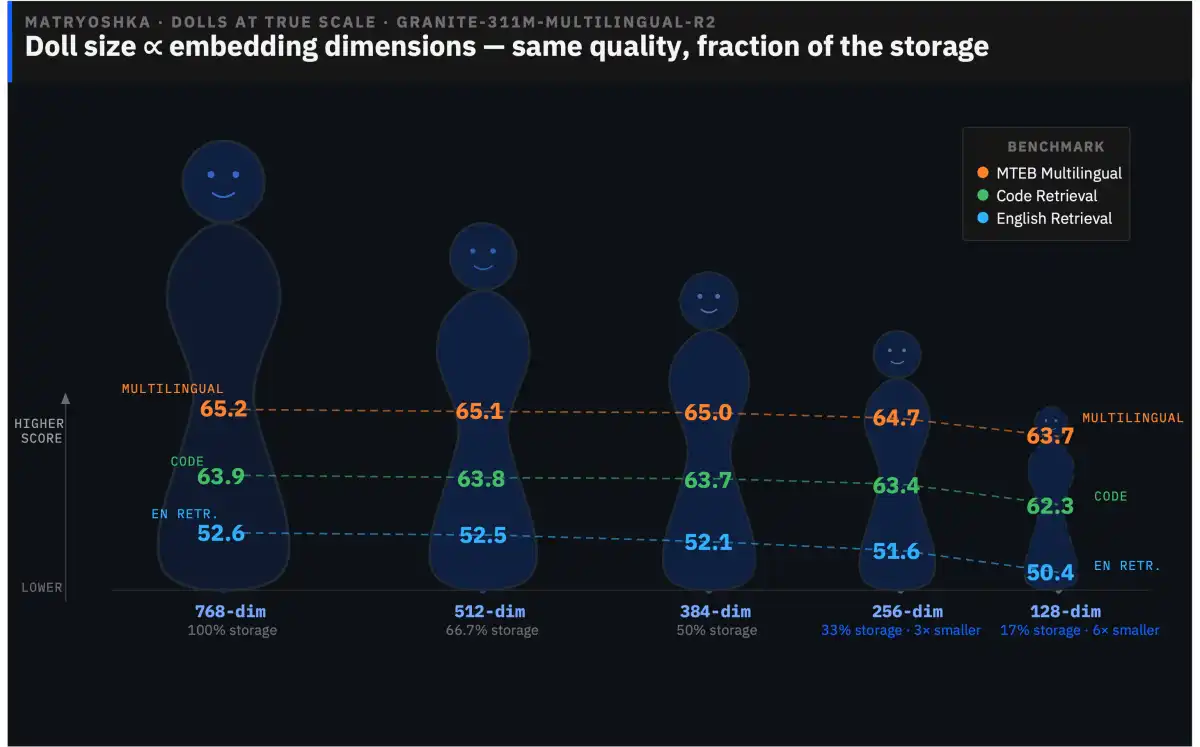
IBM has just released the Granite Embedding Multilingual R2, a pair of open-source multilingual embedding models that promise to revolutionize the way we approach search and retrieval in multiple languages. The models, which are licensed under Apache 2.0, boast a massive 32,768-token context window, making them capable of handling long-form documentation and even entire chapters as single units.
What This Actually Does
An embedding model is essentially a digital "vibe check" for your data. When you feed it a sentence, it turns that text into a long string of numbers (a vector) that represents its meaning. If two sentences mean the same thing – even if they use different words or different languages – their numbers will sit very close to each other in mathematical space.
Before Granite R2, most open-source embedding models had a tiny "memory." They could only look at about 512 tokens at a time. This meant that if you had a 20-page PDF, you had to chop it into tiny pieces, which often destroyed the context. Plus, if you wanted it to work in Greek or Hindi, the accuracy usually fell off a cliff.
Background and Context
The Granite Embedding Multilingual R2 is built on ModernBERT, the current gold standard for "encoder" models. It covers over 200 languages out of the box, with deep training for the 52 most common ones (including Arabic, Chinese, French, and German). It even handles nine different programming languages, making it a beast for searching through code repositories.
IBM is giving us two new models – a tiny 97M compact version and a punchy 311M version – both licensed under Apache 2.0. This means that you can use them for commercial projects without paying a cent in licensing or per-token fees. The wild part? They've bumped the context window to 32,768 tokens.
Why It Matters to the Industry
The promise of an open-source, multilingual retrieval model that actually works is... well, it's a lot to process. For us ML engineers drowning in data, especially those staring down the barrel of global e-commerce platforms, this is 'right now' tech that simplifies your stack and slashes your cloud bill in one go.
That 32K window isn't free, though. Processing that much data per inference call means more compute, more memory, and potentially, higher latency. Are your existing retrieval pipelines, often optimized for shorter, punchier inputs, ready for this? Or are you going to be chunking down even those seemingly "long" inputs, negating some of the benefit?
What Comes Next
The strategy here isn't just about having a big context window; it's about effectively utilizing it without breaking your latency budget or racking up cloud bills. For a global e-commerce platform with millions of SKUs and potentially thousands of concurrent searches, this is a critical trade-off.
Key Facts
- The Granite Embedding Multilingual R2 boasts a massive 32,768-token context window.
- The models are licensed under Apache 2.0, making them free for commercial use.
- The models cover over 200 languages out of the box, with deep training for the 52 most common ones.
- They even handle nine different programming languages.
- The compact version has 97M parameters, while the full-size model has 311M parameters.
IBM's Granite Embedding Multilingual R2 is a game-changer for search and retrieval in multiple languages. With its massive context window and deep training for over 200 languages, it promises to revolutionize the way we approach search and retrieval. But will it live up to the hype? Only time will tell.