A new technique called Mixture of Experts (MoE) has emerged as a game-changer for scaling dense language models, allowing them to process vast amounts of data while reducing computational complexity and memory requirements. MoE models have been gaining traction in recent months, with several major releases in the past few weeks, including Qwen 3.5, MiniMax M2, GLM-5, and Kimi K2.
What is Mixture of Experts (MoE)?
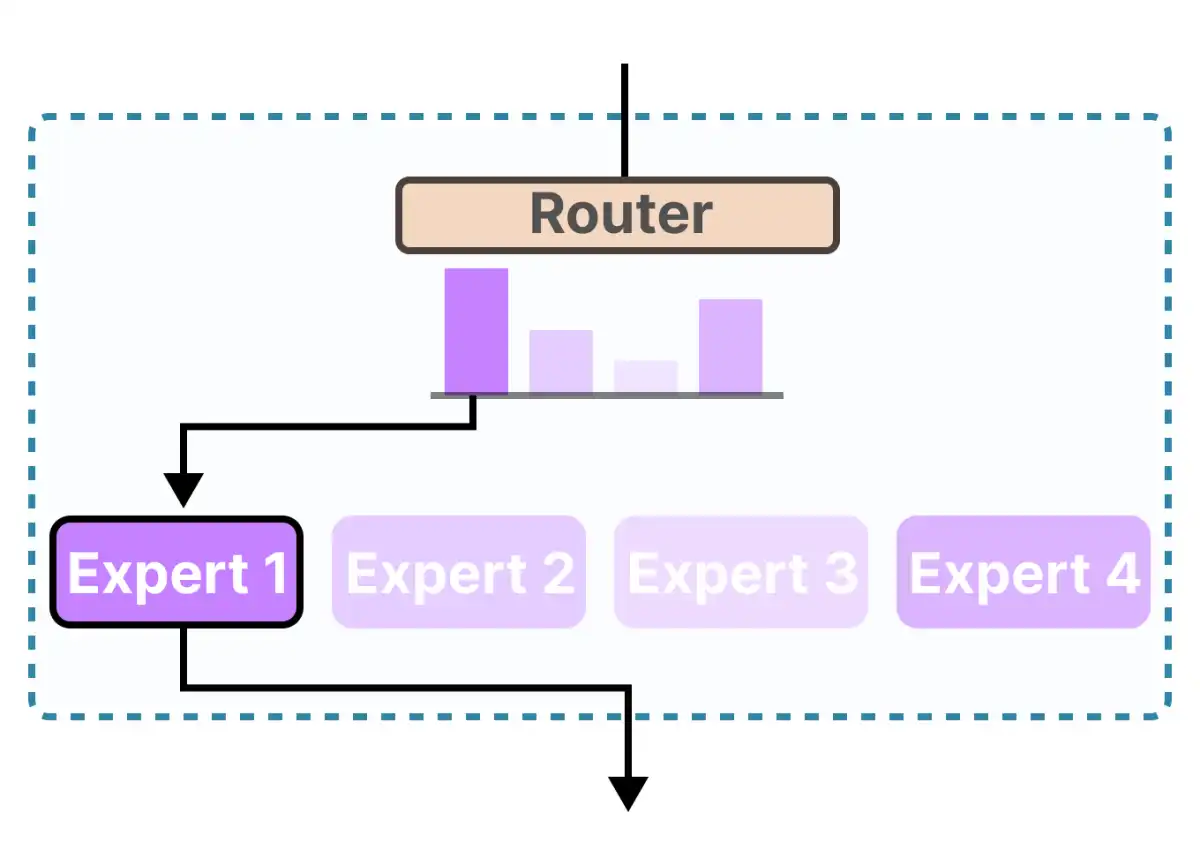
MoE models are a type of neural network architecture that combines multiple expert networks to process input data. Each expert network specializes in processing specific types of information, and the MoE model selects which experts to use for each input based on their hidden representations. This approach allows MoE models to achieve state-of-the-art performance while reducing computational complexity and memory requirements.
The key idea behind MoE is that different tokens activate different experts, based on their hidden representations. Model capacity depends on total parameters, but inference speed depends on active parameters. For example, take gpt-oss-20b, which has 21B total parameters but uses 4 active experts per token, out of a total of 32 experts. Considering the shared components plus the active experts, this model uses ~3.6B active parameters per token.
Why MoE Matters to the Industry
MoE models have significant implications for the adult industry, particularly in terms of scalability and efficiency. As streaming and webcam infrastructure continues to grow, the need for more efficient and scalable solutions becomes increasingly important. MoE models offer a promising solution by reducing computational complexity and memory requirements, making them ideal for large-scale deployments.
Moreover, MoE models can be trained using significantly less data than traditional dense language models, which is particularly beneficial in industries where data collection and annotation are challenging. This makes MoE models an attractive option for companies looking to deploy large-scale language models without breaking the bank.
Background and Context
MoE models have their roots in the machine learning community, where they were first introduced as a technique for combining multiple expert networks to process input data. However, it wasn't until recently that MoE models gained traction in the natural language processing (NLP) community.
The success of DeepSeek R1 in January 2025 marked a turning point for MoE models, demonstrating their potential for large-scale NLP tasks. Since then, several major releases have followed, including Qwen 3.5, MiniMax M2, GLM-5, and Kimi K2.
What Comes Next?
The adoption of MoE models is expected to continue in the coming months, with several companies already exploring their potential for large-scale NLP tasks. However, there are still challenges to be addressed, particularly in terms of training and deploying MoE models at scale.
To address these challenges, researchers and developers are working on improving the efficiency and scalability of MoE models. This includes developing new techniques for training and deploying MoE models, as well as exploring their potential applications in various industries.
Key Facts
- Mixture of Experts (MoE) is a type of neural network architecture that combines multiple expert networks to process input data.
- MoE models have been gaining traction in recent months, with several major releases in the past few weeks.
- MoE models can be trained using significantly less data than traditional dense language models.
- Moe models offer a promising solution for large-scale deployments by reducing computational complexity and memory requirements.
- The adoption of MoE models is expected to continue in the coming months, with several companies already exploring their potential for large-scale NLP tasks.