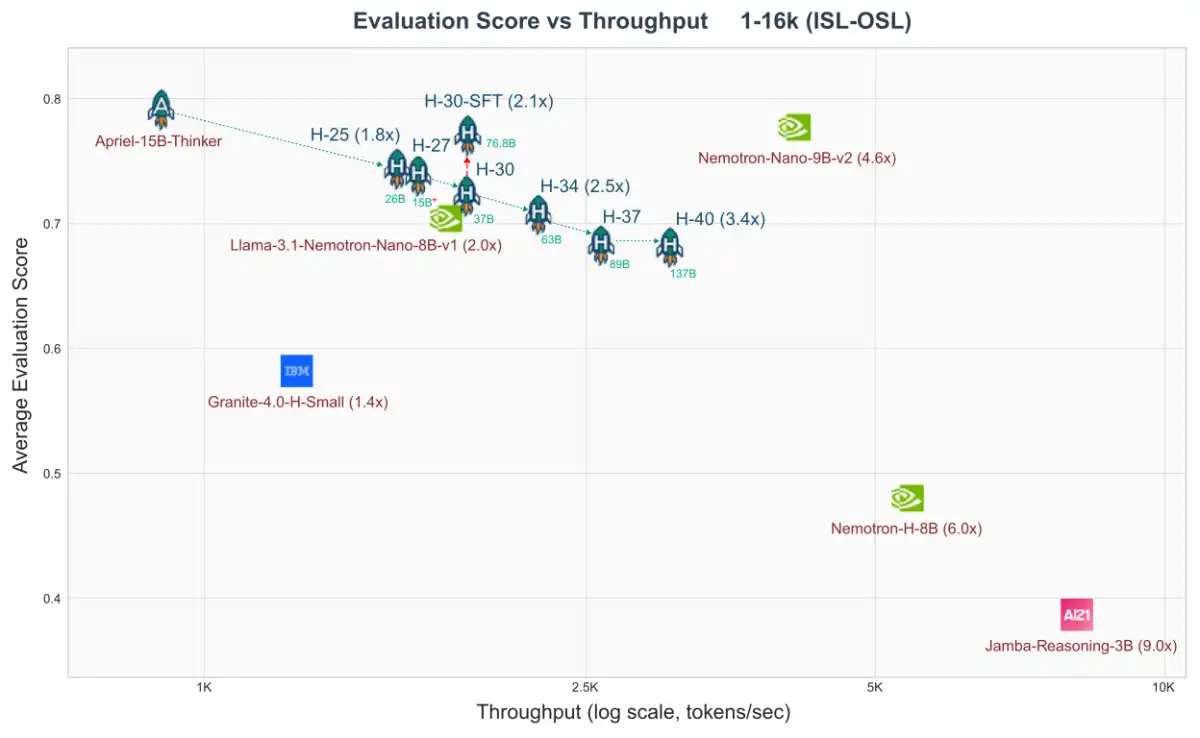
The Apriel-H1 family of hybrid language models has been released by ServiceNow's SLAM Lab, offering a significant boost in efficiency and scalability for large-scale reasoning tasks. The models combine transformer attention mechanisms with State Space Models (SSMs) like Mamba to achieve linear inference complexity and constant memory footprint.
According to the research paper published on arXiv, the Apriel-H1 family was obtained through incremental distillation from a pretrained reasoning transformer, Apriel-Nemotron-15B-Thinker. The models were progressively replacing less critical attention layers with linear Mamba blocks, resulting in substantial efficiency gains over the pretrained transformer equivalent.
Background and Context
The transformer architecture has become the de facto standard for large-scale language modeling (LLMs), powering state-of-the-art models like Apriel. However, the throughput of transformer inference models is largely limited due to the quadratic complexity of the attention module, as well as the necessity to cache and retrieve key and value representations of preceding tokens into fast GPU memory during each forward computation.
These throughput constraints can become a critical bottleneck in the practical adoption of LLMs, particularly in scenarios with high request loads, multi-user environments, as well as for tasks that require the model to consume large prompts and generate long output traces. The latter is especially relevant for agentic tasks with long contexts and reasoning traces.
The researchers behind Apriel-H1 aimed to address these challenges by exploring alternative architectures that can achieve linear inference complexity and constant memory footprint. They introduced the concept of hybrid LLMs, combining transformer attention mechanisms with SSMs like Mamba, which offer a promising alternative to traditional transformer-based models.
Why it Matters to the Industry
The release of Apriel-H1 has significant implications for the adult industry, where large-scale reasoning tasks are increasingly common. The ability to efficiently process and generate long output traces is crucial for applications such as content moderation, chatbots, and recommendation systems.
Moreover, the scalability and efficiency gains offered by Apriel-H1 can help reduce the computational resources required for these tasks, making it more feasible for smaller platforms and operators to implement large-scale reasoning models. This can lead to improved user experiences, increased revenue opportunities, and enhanced competitiveness in the market.
What Comes Next
The researchers behind Apriel-H1 have made their models and training framework available on GitHub, allowing developers to reproduce and build upon their work. The team is also exploring the use of reinforcement learning (RL) to further improve the efficiency and quality of hybrid LLMs.
As the adult industry continues to adopt large-scale reasoning tasks, the release of Apriel-H1 marks an important milestone in the development of efficient and scalable language models. The implications of this research are far-reaching, and it will be exciting to see how the industry responds to these advancements.
Key Facts
- The Apriel-H1 family of hybrid language models combines transformer attention mechanisms with State Space Models (SSMs) like Mamba.
- The models achieve linear inference complexity and constant memory footprint, offering significant efficiency gains over traditional transformer-based models.
- Apriel-H1 was obtained through incremental distillation from a pretrained reasoning transformer, Apriel-Nemotron-15B-Thinker.
- The researchers behind Apriel-H1 have made their models and training framework available on GitHub for reproduction and further development.
- The team is exploring the use of reinforcement learning (RL) to further improve the efficiency and quality of hybrid LLMs.