The landscape of artificial intelligence is undergoing a profound transformation. While Large Language Models (LLMs) have captivated the world with their ability to generate human-like text, the next frontier lies in empowering these models with true agency – the capacity to understand, plan, execute, and adapt to complex tasks autonomously. This evolution, often termed 'Agentic Reinforcement Learning' (RL), promises to elevate LLMs from sophisticated text generators to intelligent, goal-directed agents capable of interacting with dynamic environments and utilizing external tools.
The convergence of Agentic RL with GPT-OSS (GPT-Open Source Software) models presents an unparalleled opportunity: to build highly capable, customizable, and transparent AI agents without proprietary constraints. Projects like Llama, Mistral, and Falcon have put advanced LLM technology into the hands of developers and researchers worldwide.
**The Paradigm Shift: Understanding Agentic Reinforcement Learning**
To appreciate the power of Agentic RL, it's crucial to first grasp the foundational principles of Reinforcement Learning and then understand what 'agentic' truly implies in this context. Reinforcement Learning is a machine learning paradigm where an 'agent' learns to make decisions by interacting with an 'environment'. The agent performs 'actions' in a given 'state' of the environment, and in response, receives a 'reward' signal and transitions to a new state.
The ultimate goal of the agent is to learn a 'policy' – a mapping from states to actions – that maximizes the cumulative reward over time. In Agentic RL, this policy is not limited to text generation but extends to complex tasks such as tool usage, web browsing, and code execution across multi-turn trajectories.
**The Problem with Current Open-Source Approaches**
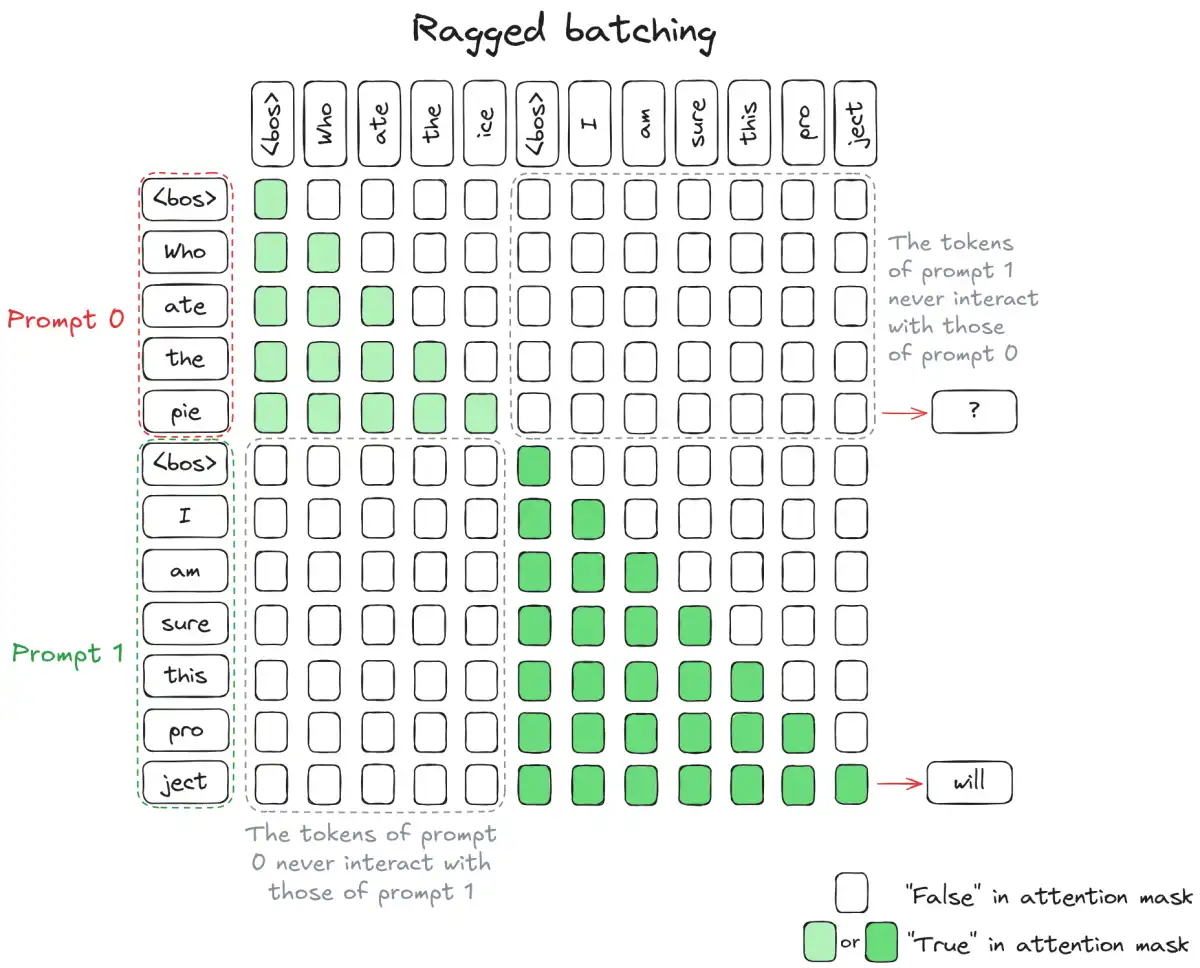
Existing open-source RL training frameworks were not designed for the new regime of LLM post-training. Synchronous RL (e.g., VERL) suffers from significant GPU idle time due to the batch completion requirement before training can begin. Asynchronous approaches attempt to keep GPUs busy by overlapping rollout and training stages but introduce problems such as rollout-training mismatch, off-policy staleness, and data distribution instability.
**Unlocking Efficiency with SFR-RL**
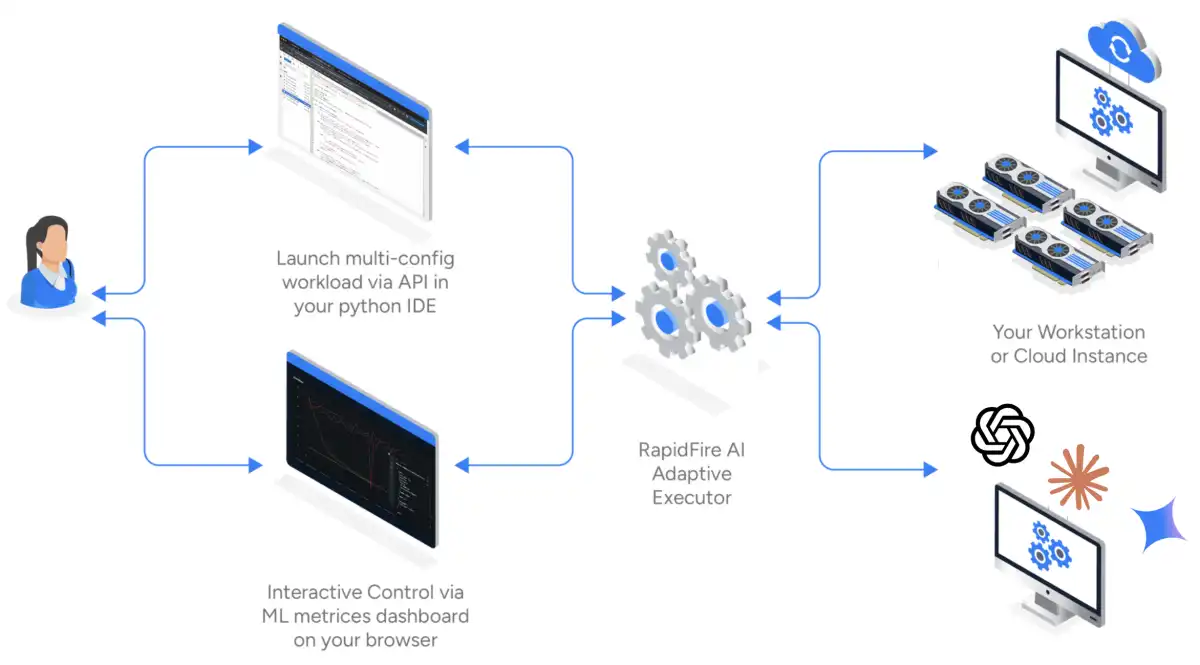
Salesforce AI Research has built SFR-RL, a production-grade RL training stack purpose-built for agentic RL at scale. The design decisions behind SFR-RL aim to achieve near-100% GPU utilization across the entire cluster, train large MoE models at long context lengths with fewer GPUs than previously possible, and scale tool calling to thousands of concurrent executions with minimal cost.
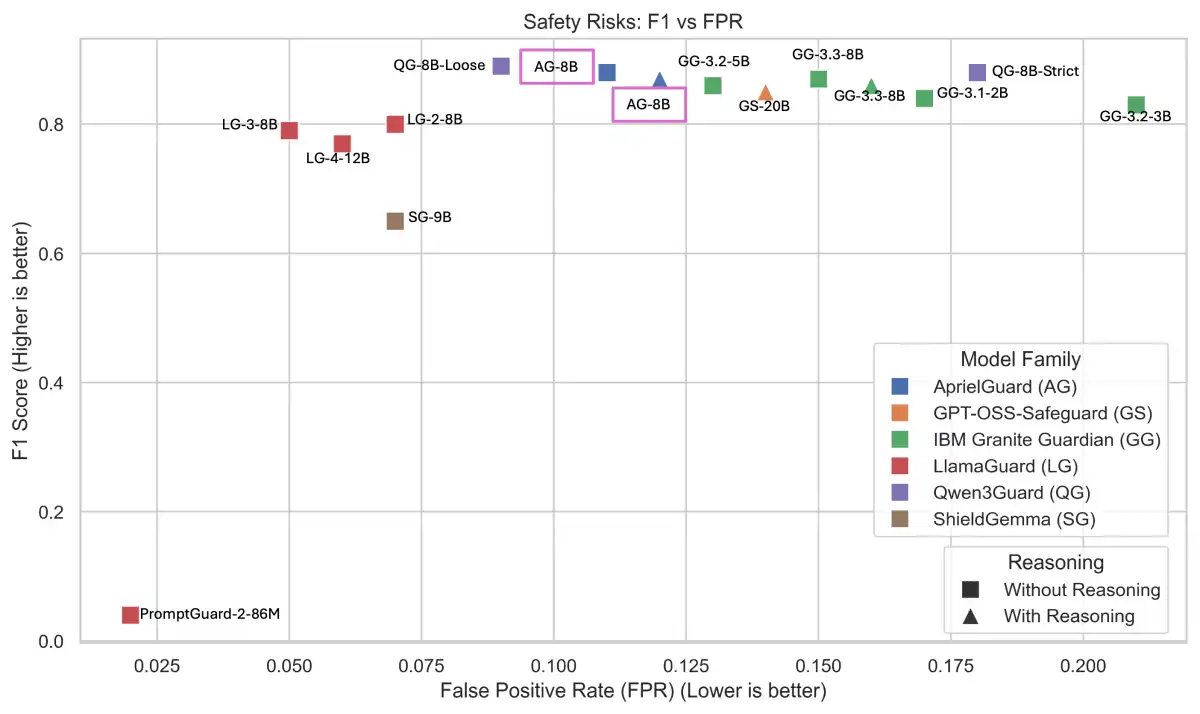
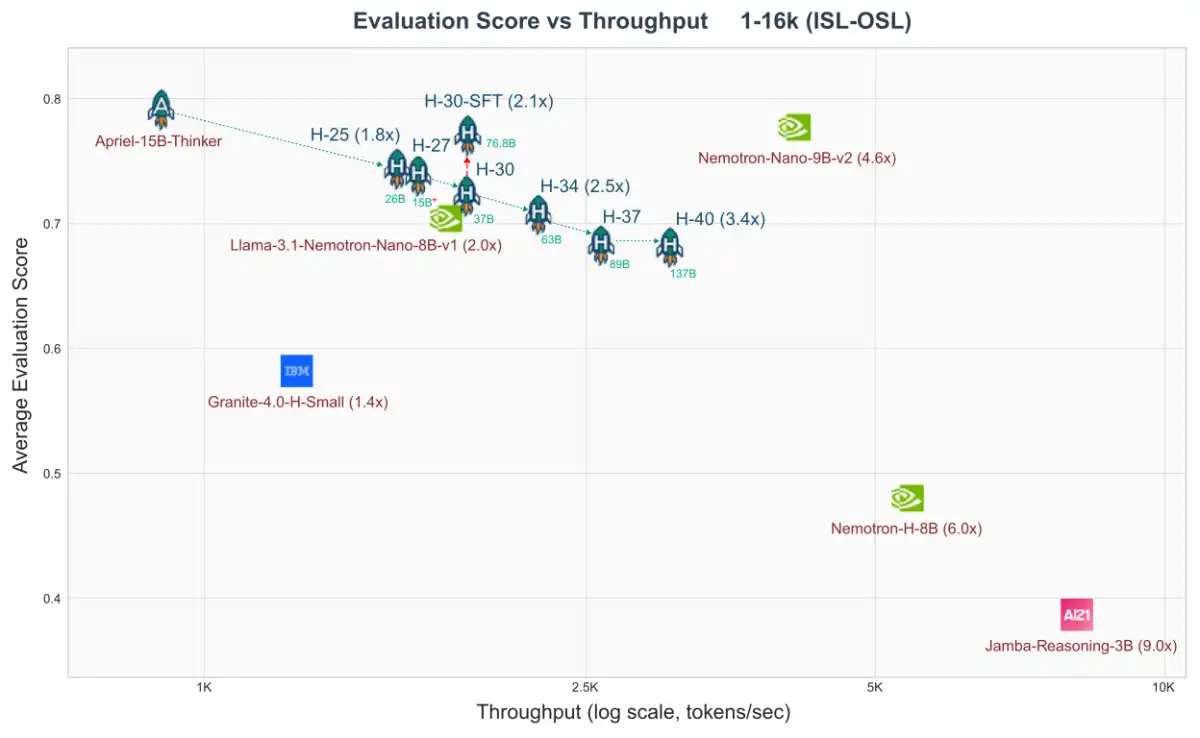
**Benchmark Results**
Early benchmark results from Salesforce AI Research show significant throughput improvements over existing approaches. SFR-RL demonstrates its efficiency in handling agentic workloads, where trajectory lengths can range from a few hundred tokens to tens of thousands.
**GPT-OSS Reinforcement Learning with Unsloth**
Unsloth offers the fastest inference (3x faster), lowest VRAM usage (50% less) and longest context (8x longer) for gpt-oss RL vs. any implementation – with no accuracy degradation. Unsloth's unique weight sharing, Flex Attention, Standby, and custom kernels contribute to its performance gains.
**Key Facts**
- **SFR-RL**: A production-grade RL training stack purpose-built for agentic RL at scale.
- **Agentic RL**: Empowers LLMs with true agency – the capacity to understand, plan, execute, and adapt to complex tasks autonomously.
- **GPT-OSS**: Open-source software models that have democratized access to powerful AI capabilities.
- **Unsloth**: Offers the fastest inference (3x faster), lowest VRAM usage (50% less) and longest context (8x longer) for gpt-oss RL vs. any implementation – with no accuracy degradation.
- **SFR-RL's Goals**: Achieve near-100% GPU utilization, train large MoE models at long context lengths with fewer GPUs than previously possible, and scale tool calling to thousands of concurrent executions with minimal cost.
**Conclusion**
The convergence of Agentic RL with GPT-OSS presents an unparalleled opportunity for building highly capable, customizable, and transparent AI agents without proprietary constraints. The efficiency improvements brought by SFR-RL and the performance gains offered by Unsloth demonstrate the potential of this synergy. As we move forward in the agentic era, it is crucial to address the challenges posed by current open-source approaches and leverage innovative solutions like SFR-RL and Unsloth to unlock the full potential of Agentic RL for GPT-OSS.