The adult industry's reliance on AI-powered tools and services has led to a growing need for benchmarking and evaluation of these systems' performance. A recent blog post by Nathan Habib and Pedro Cuenca introduces a tool called "agent-eval" that measures how well coding agents can use software libraries, specifically the transformers library.
What Happened
The authors of the blog post, Nathan Habib and Pedro Cuenca, aimed to create a benchmarking tool that would evaluate the performance of coding agents on various tasks. They used the transformers library as their case study and created a harness that measures how well an agent can perform a task using different metrics such as time, tokens, and errors.
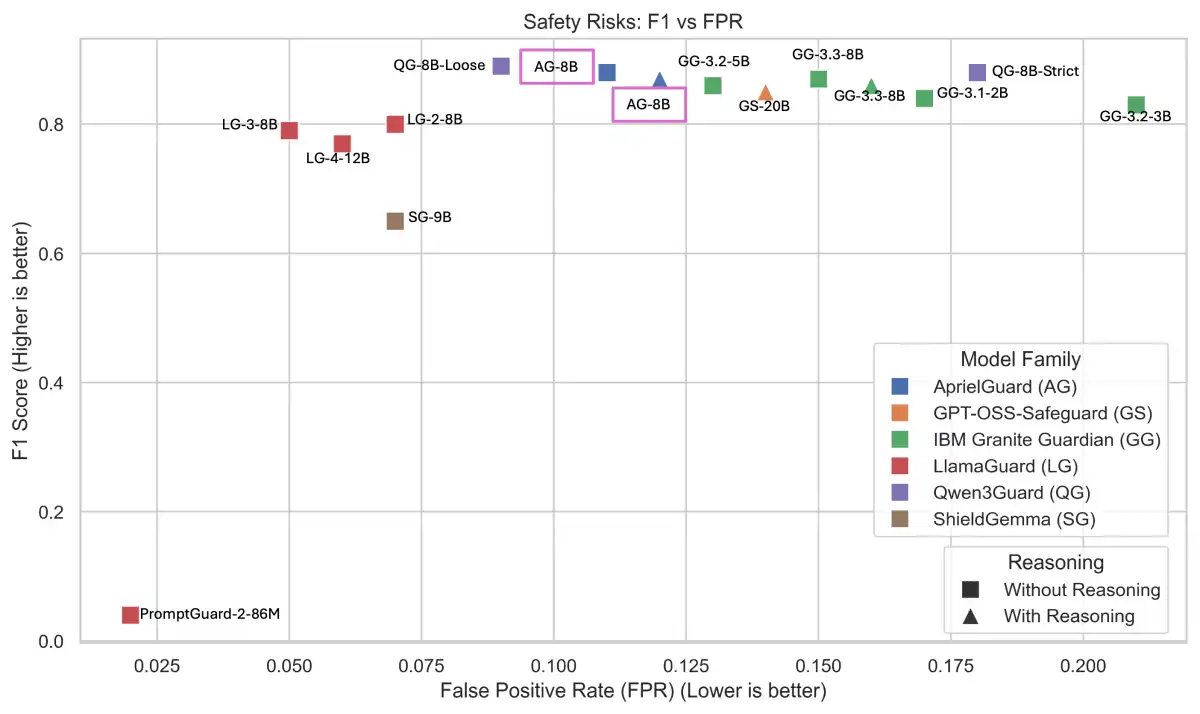
The authors ran the harness on 21 system variants, including large open models, local models, and smaller models. They found that the effort it took for the agent to get the correct result was more relevant than just measuring the final answer. The results showed that the Skill commit in the transformers library reduced the time spent by agents working on tasks, but also increased token consumption due to the new CLI code being read by the agent.
Background and Context
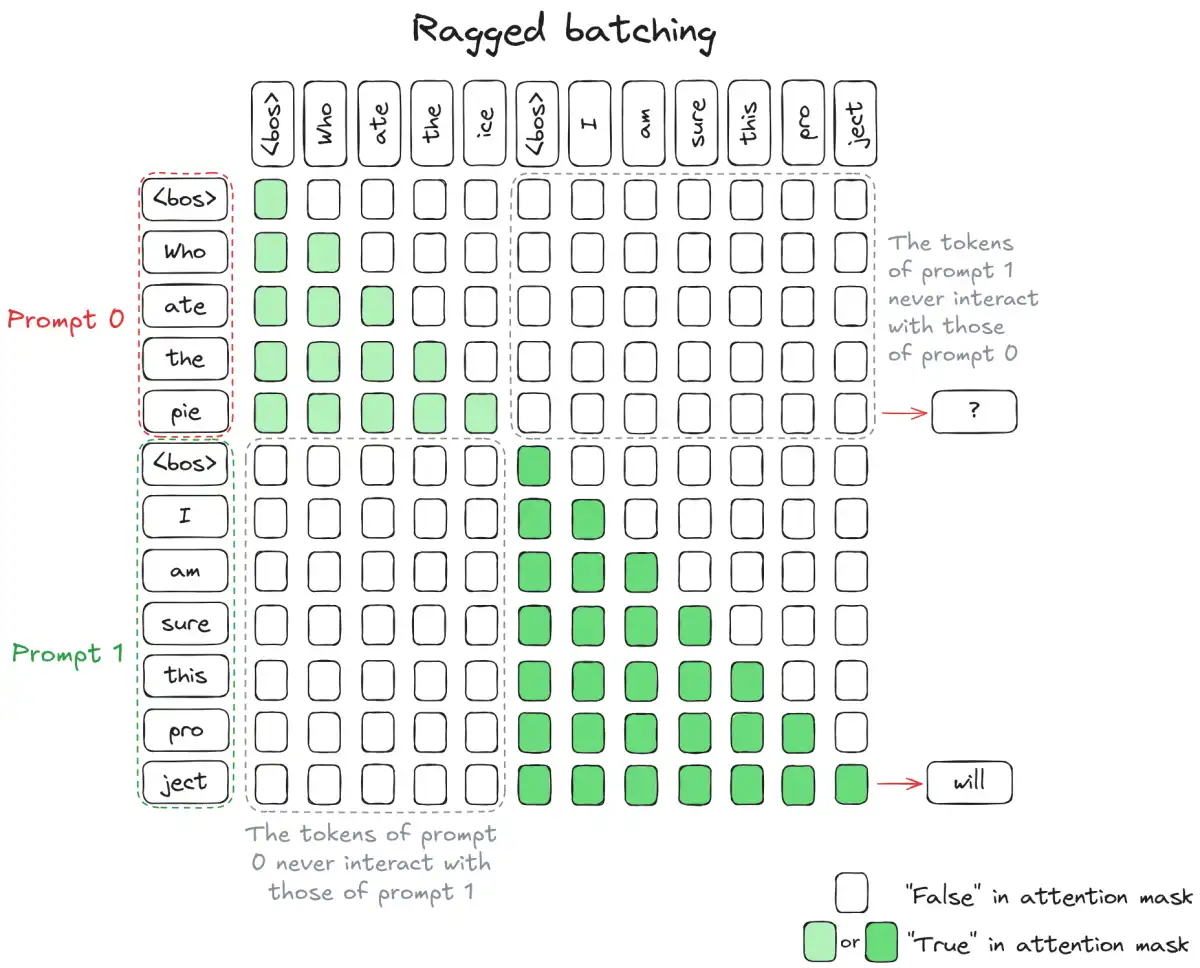
The transition from Cloud-Native to AI-Native architectures has led to a shift in software engineering, where deterministic microservices are replaced with probabilistic agentic services. This shift requires new evaluation paradigms that go beyond traditional black-box metrics. The authors of the blog post cite a recent paper by Zirui Wang et al., which introduces AI-NativeBench, a white-box benchmark suite for AI-Native systems.
AI-NativeBench measures system-level execution dynamics and treats agentic spans as first-class citizens within distributed traces. The authors found that traditional metrics such as model capability are insufficient to evaluate the performance of AI-Native systems. They discovered a parameter paradox where lightweight models often surpass flagships in protocol adherence, and an expensive failure pattern where self-healing mechanisms act as cost multipliers on unviable workflows.
Why It Matters
The results of the harness have significant implications for the adult industry's reliance on AI-powered tools and services. The authors found that the Skill commit in the transformers library helps large models but hurts smaller ones, which could lead to incorrect or incomplete results. This highlights the need for careful evaluation and testing of AI systems before deployment.
The harness also provides a framework for evaluating other software libraries and tools used in the adult industry. By measuring how well coding agents can use these libraries, developers can identify areas for improvement and optimize their code for better performance.
What Comes Next
The authors of the blog post provide instructions on how to install and run the harness on other software libraries and tools. They also encourage users to contribute to the development of the harness and share their results with the community.
Key Facts
- The "agent-eval" tool measures how well coding agents can use software libraries, specifically the transformers library.
- The authors ran the harness on 21 system variants, including large open models, local models, and smaller models.
- The Skill commit in the transformers library reduced the time spent by agents working on tasks but increased token consumption.
- Traditional metrics such as model capability are insufficient to evaluate the performance of AI-Native systems.
- AI-NativeBench measures system-level execution dynamics and treats agentic spans as first-class citizens within distributed traces.
The results of this study have significant implications for the development and deployment of AI-powered tools and services in the adult industry. By understanding how well coding agents can use software libraries, developers can optimize their code for better performance and ensure that their systems are reliable and accurate.