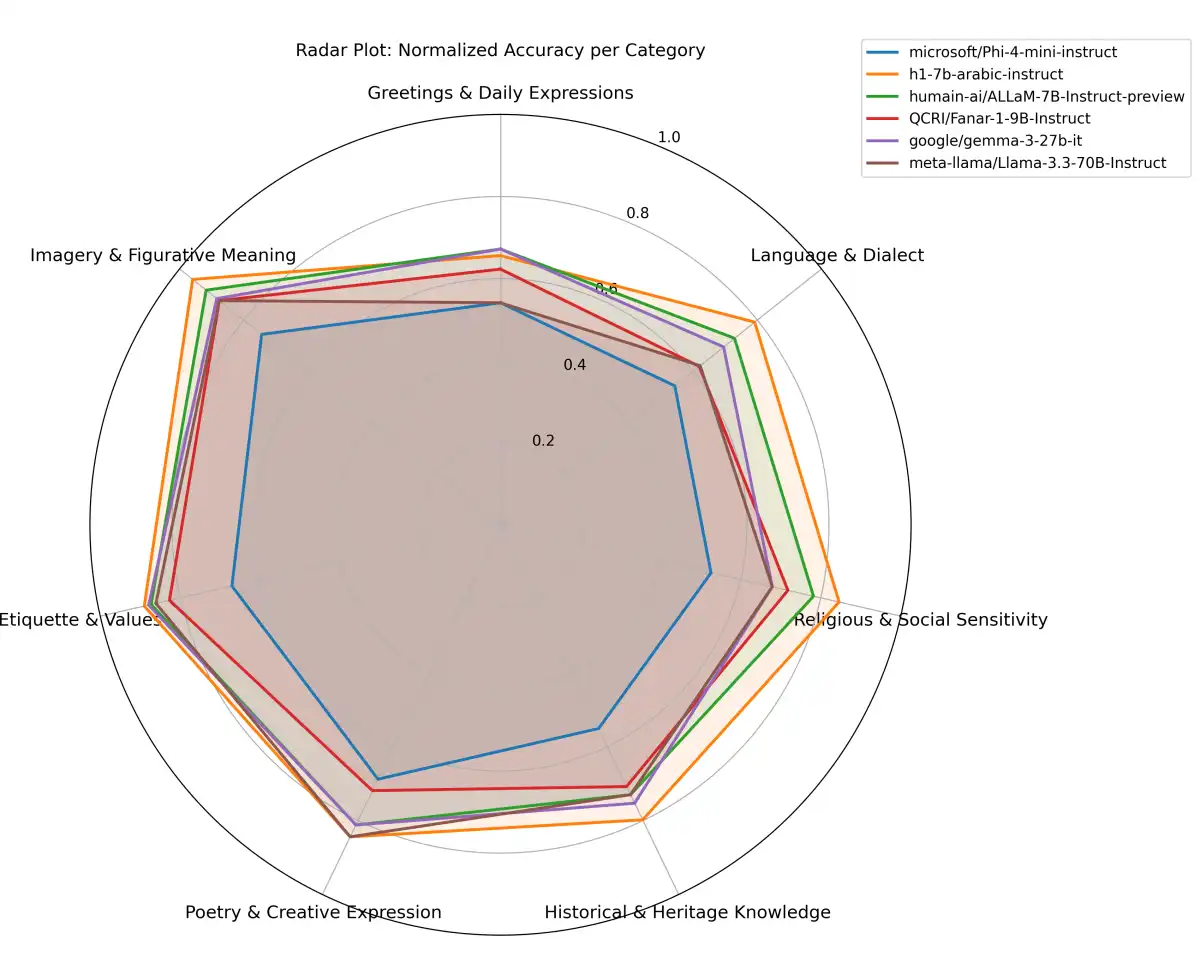
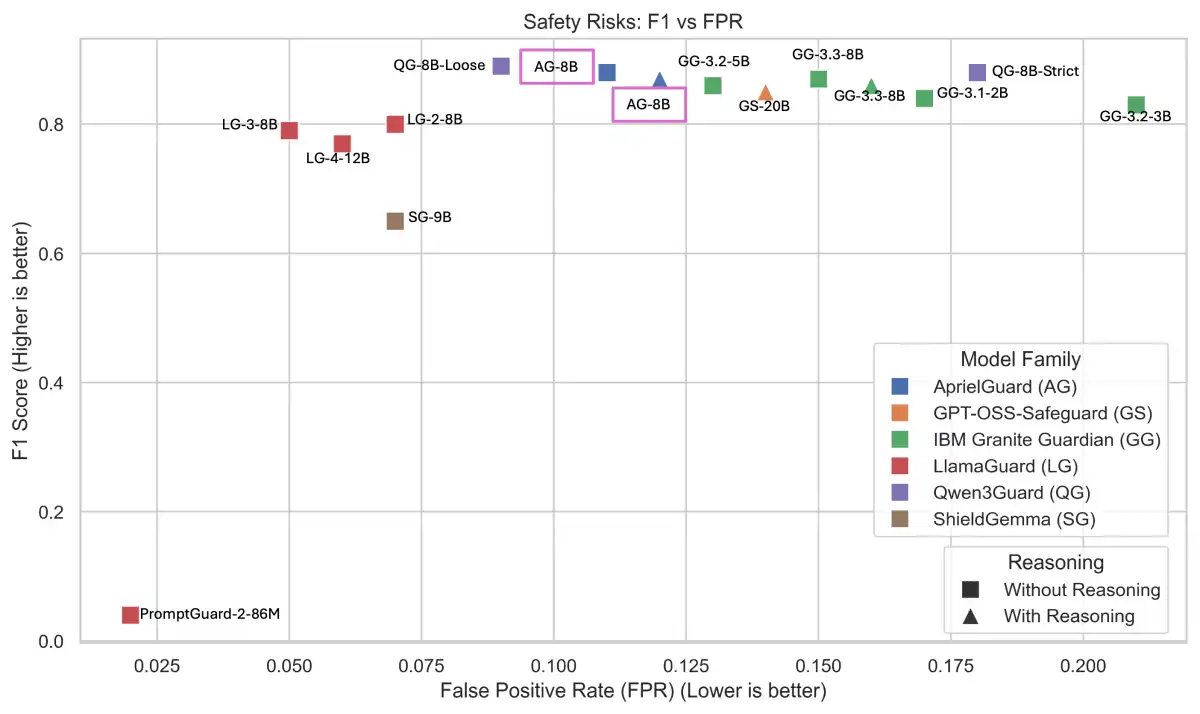
The Arabic language model landscape has seen significant advancements in recent years, driven by the increasing availability of large-scale datasets and evaluation benchmarks. However, evaluating the performance of these models remains a challenging task, particularly for low-resource languages like Arabic. To address this challenge, researchers from Inception, Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), and Hugging Face have introduced AraGen, a new generative tasks benchmark and leaderboard specifically designed for Arabic-centric large language models.
What Happened
AraGen is the result of a collaborative effort between Inception, MBZUAI, and Hugging Face to develop a comprehensive evaluation framework for Arabic LLMs. The project aims to provide a transparent, robust, and holistic assessment of these models' performance, focusing on both factual accuracy and usability in a production-ready setting. To achieve this goal, the researchers have introduced the 3C3H Measure, a new evaluation metric that assesses six dimensions: Correctness, Completeness, Conciseness, Helpfulness, Human-readability, and Heterogeneity.
The AraGen Benchmark is another key component of the project, providing a meticulously constructed evaluation dataset for Arabic LLMs. This benchmark includes a range of tasks, such as text generation, summarization, and question-answering, designed to evaluate the models' ability to perform complex linguistic tasks in Arabic. The AraGen Leaderboard's dynamic benchmarking system allows users to compare model performance across different evaluation metrics, providing a more comprehensive understanding of each model's strengths and weaknesses.
Background and Context
The development of Arabic-centric large language models is a complex task, requiring significant resources and expertise. The scarcity of high-quality training data and the limited availability of evaluation benchmarks have hindered progress in this area. To address these challenges, researchers have been working to develop new evaluation frameworks and datasets specifically designed for Arabic LLMs.
One notable example is the Open Arabic LLM Leaderboard (OALL), which provides a comprehensive overview of leaders in the field. The OALL uses several datasets, most of them translated to Arabic, and validated by native Arabic speakers. Another example is the AlGhafa Evaluation Benchmark for Arabic Language Models, introduced at the 2023 ArabicNLP conference. This benchmark includes a collection of publicly available datasets, as well as a newly introduced HandMade dataset consisting of 8 billion tokens.
Why it Matters to the Industry
The introduction of AraGen is significant for several reasons. Firstly, it provides a much-needed evaluation framework specifically designed for Arabic LLMs, addressing the scarcity of high-quality training data and evaluation benchmarks in this area. Secondly, the 3C3H Measure offers a comprehensive assessment of model performance, focusing on both factual accuracy and usability in a production-ready setting.
The AraGen Benchmark and Leaderboard also offer several benefits to the industry. By providing a dynamic benchmarking system, users can compare model performance across different evaluation metrics, gaining a more comprehensive understanding of each model's strengths and weaknesses. This will enable researchers and developers to make informed decisions about which models best suit their needs.
What Comes Next
The introduction of AraGen marks an important milestone in the development of Arabic-centric large language models. As the field continues to evolve, it is likely that we will see further advancements in evaluation frameworks and datasets specifically designed for Arabic LLMs. The AraGen project has already sparked interest among researchers and developers, with several organizations expressing their intention to contribute to the project.
Key Facts
- AraGen is a new generative tasks benchmark and leaderboard specifically designed for Arabic-centric large language models.
- The 3C3H Measure is a new evaluation metric that assesses six dimensions: Correctness, Completeness, Conciseness, Helpfulness, Human-readability, and Heterogeneity.
- AraGen includes the AraGen Benchmark, a meticulously constructed evaluation dataset for Arabic LLMs, and the AraGen Leaderboard's dynamic benchmarking system.
- The project is the result of a collaborative effort between Inception, MBZUAI, and Hugging Face.
- AraGen aims to provide a transparent, robust, and holistic assessment of Arabic LLMs' performance, focusing on both factual accuracy and usability in a production-ready setting.