IBM's Granite 4.1 models offer strong performance in various tasks and are designed to address limitations of larger mixture-of-experts models. This open-source language model is particularly beneficial for the adult industry.
Background and Context
The development of large language models has been a rapidly evolving field in recent years. With the rise of transformer architectures and the availability of massive datasets, researchers have been able to train models that can perform a wide range of tasks with high accuracy. However, as these models grow in size and complexity, they also become increasingly difficult to train and deploy.
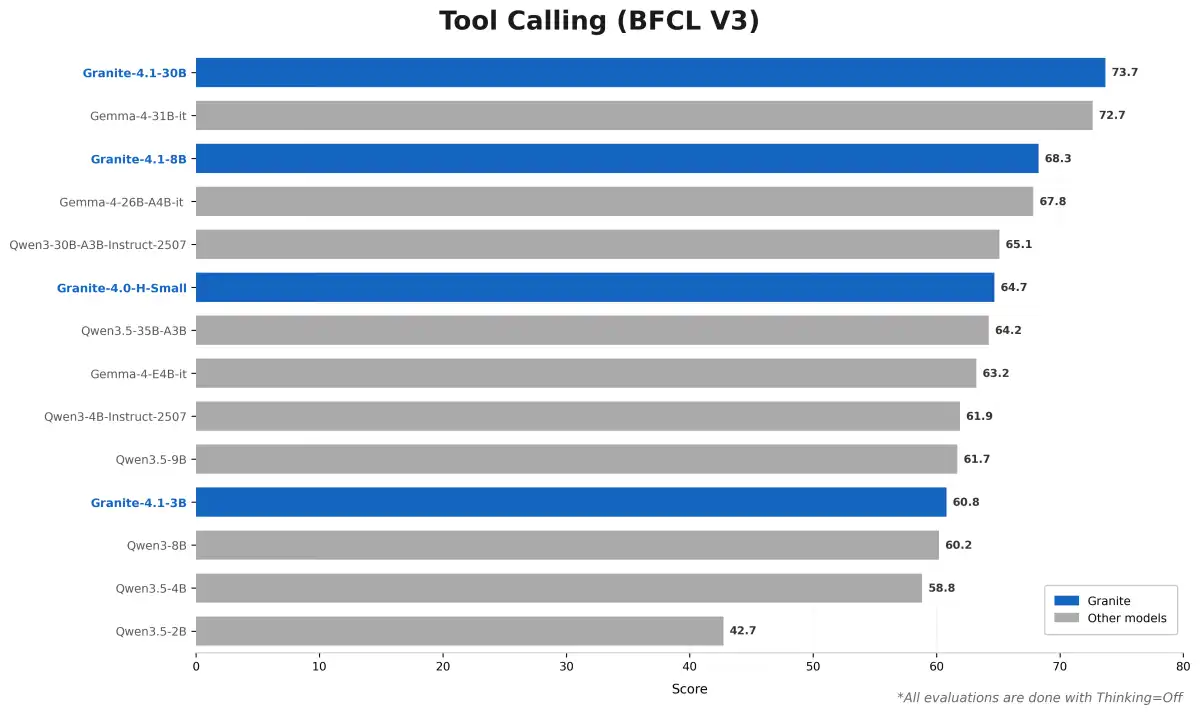
IBM's Granite 4.1 models are designed to address some of the limitations of larger mixture-of-experts models. By using a dense architecture and focusing on data quality rather than scale, IBM's team has been able to achieve performance that is comparable to or even surpasses that of larger models. This is particularly notable in tasks such as tool calling, instruction following, coding, and mathematical reasoning.
Why it Matters
The release of Granite 4.1 marks a significant step forward for open-source enterprise LLM competition. By prioritizing data quality and rigor at every stage of the training process, IBM's team has demonstrated that it is possible to achieve strong results without relying on massive datasets or complex architectures.
This development has important implications for the adult industry, where large language models are increasingly being used for tasks such as chatbots, search assistants, and workflow automation agents. With Granite 4.1, companies in this sector will have access to a high-quality, open-source model that can be easily integrated into their existing systems.
What Comes Next
As the adult industry continues to adopt large language models, it is likely that we will see increased demand for high-quality, open-source models like Granite 4.1. IBM's team has already released a GitHub repository and documentation for the model, making it easy for developers to get started.
In addition, the release of Granite 4.1 marks an important milestone in the development of large language models. As researchers continue to push the boundaries of what is possible with these models, we can expect to see even more innovative applications in the future.
Key Facts
- Granite 4.1 is a family of dense language models available in three sizes: 3B, 8B, and 30B parameters.
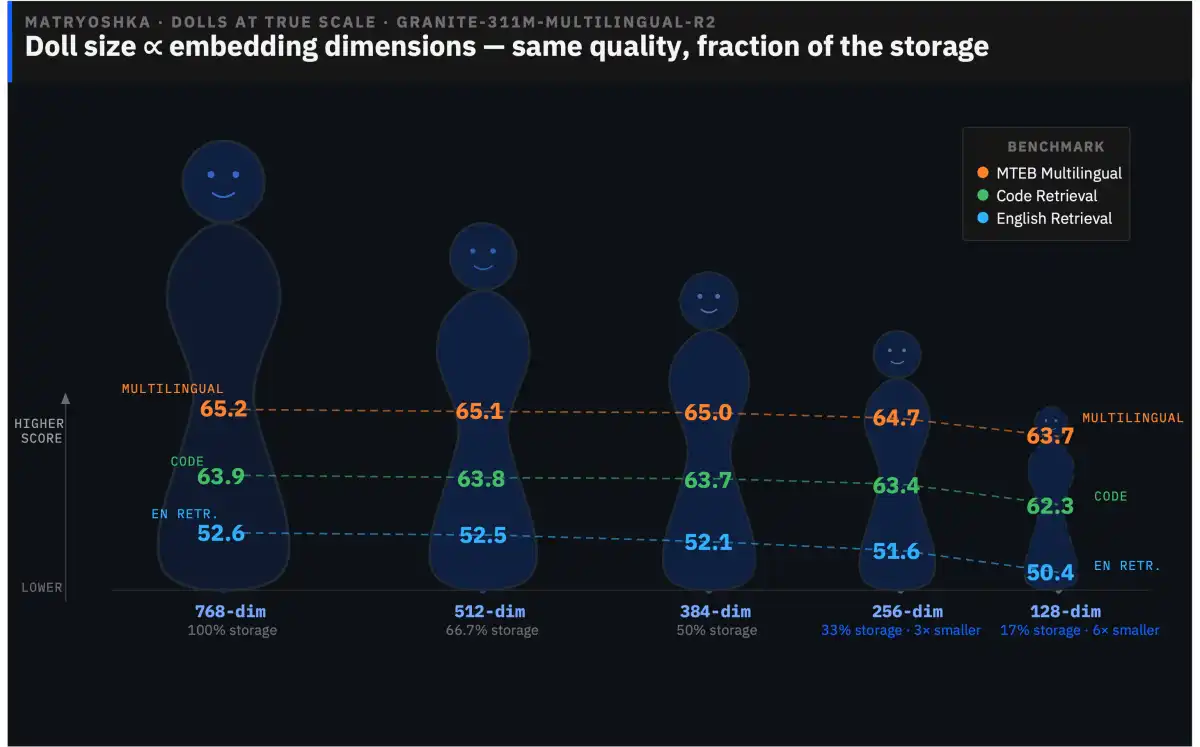
- The models were trained on approximately 15 trillion tokens of curated data using a rigorous four-stage training pipeline.
- The pre-training strategy employed a five-phase approach designed to progressively refine model capabilities.
- IBM implemented an LLM-as-Judge framework combined with rule-based filtering to detect and correct hallucinations, factual errors, and structural defects.
- The models were released under the Apache 2.0 license for unrestricted commercial and research use.
Conclusion
The release of Granite 4.1 marks a significant step forward for open-source enterprise LLM competition. By prioritizing data quality and rigor at every stage of the training process, IBM's team has demonstrated that it is possible to achieve strong results without relying on massive datasets or complex architectures.
As the adult industry continues to adopt large language models, we can expect to see increased demand for high-quality, open-source models like Granite 4.1. With its dense architecture and focus on data quality, this model is poised to become a leading choice for companies in this sector.