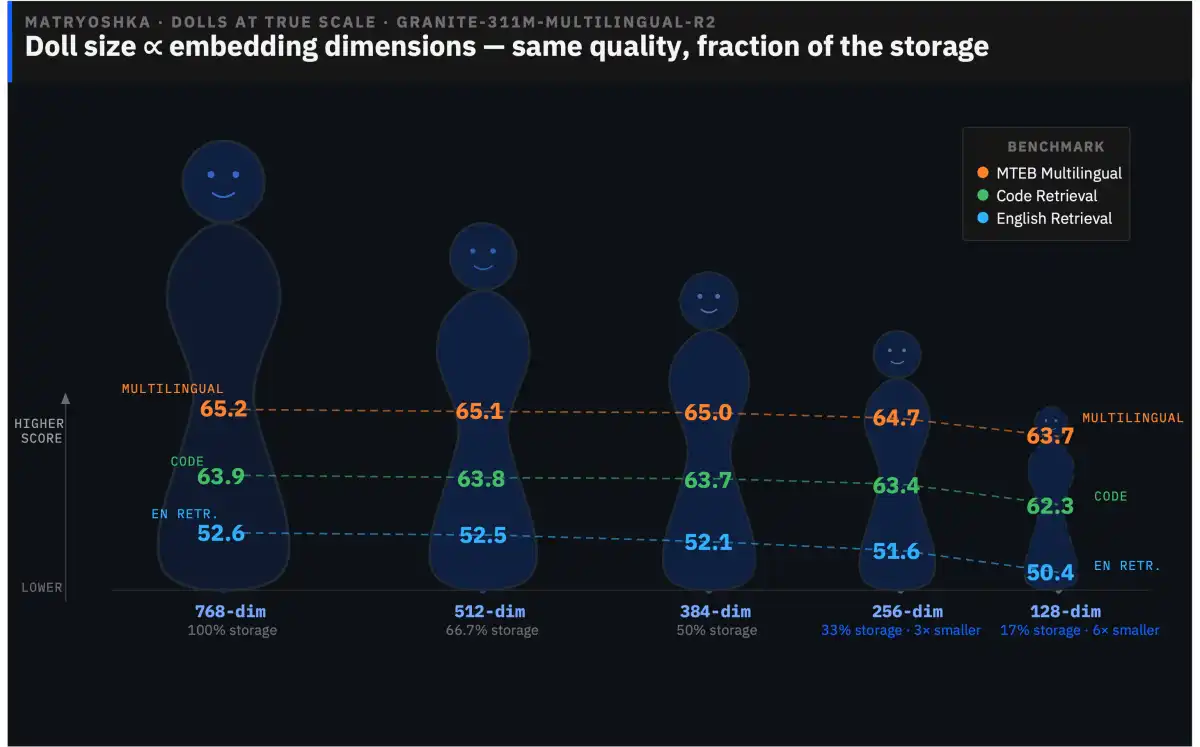
NVIDIA has released a recipe for building domain-specific embedding models in under a day, a breakthrough that could significantly improve the performance of retrieval-augmented generation (RAG) systems in various industries.
What Happened
The recipe, which is available on GitHub, uses NVIDIA's NeMo library to fine-tune a general-purpose embedding model on domain-specific data. This process involves generating synthetic training data from the domain documents using NeMo Data Designer, preparing the training data by mining hard negatives and unrolling multi-hop questions, fine-tuning the embedding model using NeMo Automodel, and evaluating the performance of the fine-tuned model using BEIR.
The recipe has been validated on real enterprise data by Atlassian, which applied it to fine-tune Llama-Nemotron-Embed-1B-v2 on a public Jira dataset using a single NVIDIA A100 80GB GPU. The results showed a significant improvement in Recall@60 from 0.751 to 0.951, a 26% gain.
Background and Context
Domain-specific embedding models are trained to understand the nuances of a specific domain or industry, which can lead to improved performance in retrieval-augmented generation (RAG) systems. However, training such models from scratch can be time-consuming and requires significant expertise.
NVIDIA's recipe aims to address this challenge by providing a streamlined process for building domain-specific embedding models using NeMo library. The recipe uses a combination of synthetic data generation, hard negative mining, and fine-tuning to adapt the general-purpose embedding model to the specific domain requirements.
Why it Matters
The ability to build domain-specific embedding models in under a day has significant implications for various industries, including the adult industry. RAG systems are widely used in content moderation, recommendation systems, and other applications where accurate retrieval of relevant information is critical.
By using domain-specific embedding models, companies can improve the performance of their RAG systems, leading to better user experiences and increased efficiency. Additionally, the recipe's ability to fine-tune general-purpose models on domain-specific data makes it an attractive solution for companies that do not have large amounts of labeled data.
What Comes Next
NVIDIA's recipe is a significant breakthrough in the field of natural language processing (NLP) and has the potential to revolutionize the way companies build and deploy RAG systems. As more companies adopt this approach, we can expect to see improved performance and efficiency in various industries.
Key Facts
- NVIDIA's recipe allows building domain-specific embedding models in under a day.
- The recipe uses NeMo library to fine-tune general-purpose embedding models on domain-specific data.
- Atlassian applied the recipe to fine-tune Llama-Nemotron-Embed-1B-v2 on a public Jira dataset and achieved a 26% gain in Recall@60.
- The recipe includes synthetic data generation, hard negative mining, and fine-tuning stages.
- NVIDIA's NeMo library is used to implement the recipe.
Conclusion
NVIDIA's recipe for building domain-specific embedding models in under a day has significant implications for various industries, including the adult industry. By using this approach, companies can improve the performance of their RAG systems and increase efficiency. As more companies adopt this approach, we can expect to see improved performance and efficiency in various industries.