DeepSpeed-Ulysses Sequence Parallelism is a method that shatters long input sequences across GPUs to enable full-attention training on contexts up to millions of tokens.
What Happened
Researchers at Microsoft have developed DeepSpeed-Ulysses, a system-level technique for training transformer models on extremely long sequence lengths. This approach leverages sequence tiling, activation checkpoint offload, and two-phase all-to-all communication to reduce per-GPU memory usage while maintaining high throughput.
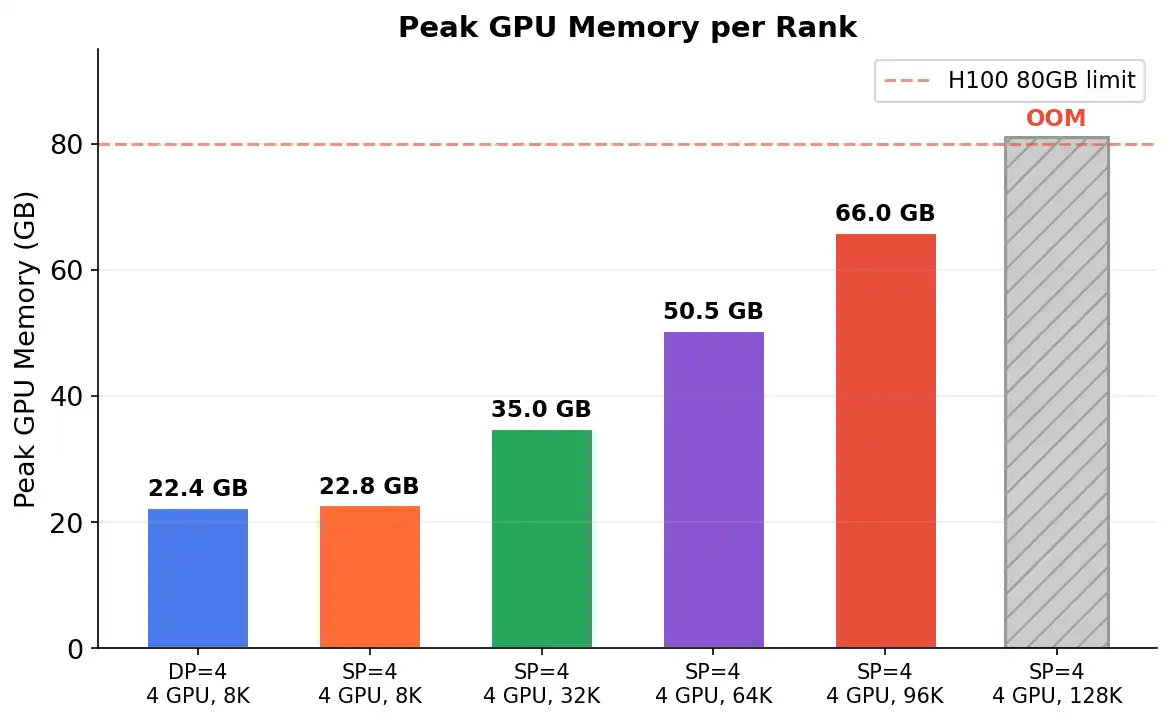
The central principle of DeepSpeed-Ulysses is sharding the input sequence along its length such that each GPU receives a local segment of the batch. This allows for efficient processing of self-attention layers, which typically require global sequence context. The two-phase all-to-all procedure involves pre-attention redistribution and self-attention computation.
Empirical results demonstrate over 400× longer context scaling for models like Llama-8B, with applications spanning NLP and high-resolution vision tasks. This breakthrough has significant implications for the industry, enabling the training of larger and more complex models that can tackle challenging tasks in areas such as conversational AI, long document summarization, and video generation.
Background and Context
Training large models with long sequences is becoming increasingly important across various domains. Generative AI applications like conversational AI, long document summarization, and video generation require reasoning over long contexts in spatial and temporal domains. Similarly, scientific discovery relies on models that can process high-dimensional inputs with extremely large sequences.
Existing parallelism approaches, such as data, tensor, and pipeline parallelism, are limited in their ability to support efficient long sequence training. These methods cannot address scaling along the sequence dimension, leading to memory-communication inefficiencies. Furthermore, existing approaches have limited usability, requiring intrusive and error-prone code refactoring.
DeepSpeed-Ulysses addresses these challenges by providing a simple, portable, and effective methodology for enabling highly efficient and scalable LLM training with extremely long sequence lengths.
Why it Matters to the Industry
The development of DeepSpeed-Ulysses has significant implications for the industry. It enables the training of larger and more complex models that can tackle challenging tasks in areas such as conversational AI, long document summarization, and video generation. This breakthrough also opens doors for better understanding of structure biology, health care, climate, and weather forecasting through large molecular simulation.
Furthermore, DeepSpeed-Ulysses integrates seamlessly with modern Hugging Face Transformers, ZeRO optimizer parameter partitioning, and high-efficiency attention kernels such as FlashAttention 2. This makes it an attractive solution for researchers and practitioners working on large-scale AI projects.
What Comes Next
The development of DeepSpeed-Ulysses marks a significant milestone in the field of deep learning. As researchers continue to push the boundaries of what is possible with AI, this breakthrough will play a crucial role in enabling the training of even larger and more complex models.
Key Facts
- DeepSpeed-Ulysses shatters long input sequences across GPUs to enable full-attention training on contexts up to millions of tokens.
- The approach leverages sequence tiling, activation checkpoint offload, and two-phase all-to-all communication to reduce per-GPU memory usage while maintaining high throughput.
- Empirical results demonstrate over 400× longer context scaling for models like Llama-8B.
- DeepSpeed-Ulysses integrates seamlessly with modern Hugging Face Transformers, ZeRO optimizer parameter partitioning, and high-efficiency attention kernels such as FlashAttention 2.
- The breakthrough has significant implications for the industry, enabling the training of larger and more complex models that can tackle challenging tasks in areas such as conversational AI, long document summarization, and video generation.