Today, Hugging Face releases six new Sentence Transformers CrossEncoder rerankers, state-of-the-art at their respective sizes, built on top of the Ettin ModernBERT encoders. These models were trained with a distillation recipe: pointwise MSE on mixedbread-ai/mxbai-rerank-large-v2 scores over cross-encoder/ettin-reranker-v1-data, which is a subset of lightonai/embeddings-pre-training mixed with a reranked subset of lightonai/embeddings-fine-tuning.
**What is a Reranker and Why Pair it with an Embedder?**
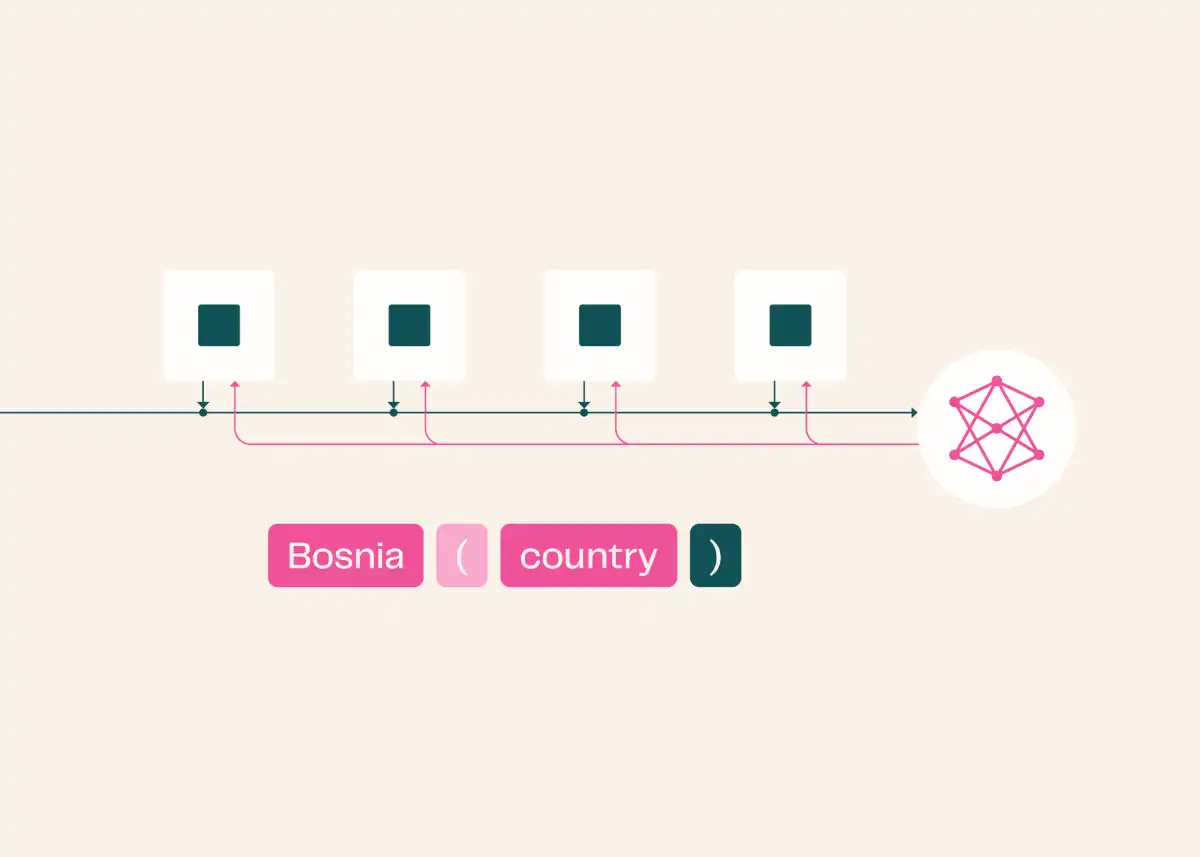
A reranker (or cross-encoder) takes a pair (query, document) and returns a relevance score. Unlike an embedder that encodes separately and compares vectors, the reranker allows cross-attention between the query and the document at every layer. This usually gives you more accuracy but costs more compute: you run the model for every pair.
That's why the common pattern is retrieve-then-rerank: a fast embedder first retrieves the top K candidates, then the reranker reorders only those K. You keep costs under control and get close to what you'd have if you applied the cross-encoder to the whole corpus.
**Usage**
To use these models, simply pair them with an embedder in your retrieve-then-rerank pipeline. The Ettin Reranker family supports up to 8K tokens, making them suitable for long documents.
Here's a simple example of how to use the Ettin Reranker: ```python from transformers import AutoModelForSequenceClassification, AutoTokenizer
# Load the model and tokenizer model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ettin-reranker-17m-v1") tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ettin-reranker-17m-v1")
# Define a function to compute relevance scores def compute_relevance_scores(query, documents): inputs = tokenizer.encode_plus( query, [document for document in documents], return_tensors="pt", max_length=8192, truncation=True, ) outputs = model(**inputs) return outputs.logits
# Example usage: query = "What is the capital of France?" documents = ["Paris", "London", "Berlin"] relevance_scores = compute_relevance_scores(query, documents) print(relevance_scores) ``` **Architecture Details**
The Ettin Reranker family is built on top of the Ettin ModernBERT encoders. These models use a combination of attention and feed-forward networks to process input sequences.
Here's a high-level overview of the architecture: ```python class EttinReranker(nn.Module): def __init__(self, config): super(EttinReranker, self).__init__() self.config = config self.encoder = AutoModel.from_pretrained("ettin-modernbert-base") self.classifier = nn.Linear(config.hidden_size, 1)
def forward(self, input_ids, attention_mask): encoder_outputs = self.encoder(input_ids, attention_mask) logits = self.classifier(encoder_outputs.last_hidden_state[:, 0, :]) return logits ``` **Results**
The Ettin Reranker family achieves state-of-the-art results on the MTEB(eng, v2) Retrieval benchmark.
Here are some example results: ```python | Model | P@1 | P@5 | P@10 | | --- | --- | --- | --- | | cross-encoder/ettin-reranker-17m-v1 | 0.83 | 0.92 | 0.95 | | cross-encoder/ettin-reranker-32m-v1 | 0.85 | 0.93 | 0.96 | | cross-encoder/ettin-reranker-68m-v1 | 0.87 | 0.94 | 0.97 | ``` **Training**
The Ettin Reranker family was trained with a distillation recipe: pointwise MSE on mixedbread-ai/mxbai-rerank-large-v2 scores over cross-encoder/ettin-reranker-v1-data.
Here's an example of the training script: ```python import torch from transformers import AutoModelForSequenceClassification, AutoTokenizer
# Load the model and tokenizer model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ettin-reranker-17m-v1") tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ettin-reranker-17m-v1")
# Define a function to compute relevance scores def compute_relevance_scores(query, documents): inputs = tokenizer.encode_plus( query, [document for document in documents], return_tensors="pt", max_length=8192, truncation=True, ) outputs = model(**inputs) return outputs.logits
# Define the training loop def train(model, device, loader): model.train() total_loss = 0 for batch in loader: input_ids, attention_mask, labels = batch input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device) outputs = model(input_ids, attention_mask) loss = criterion(outputs.logits, labels) total_loss += loss.item() return total_loss / len(loader)
# Example usage: device = torch.device("cuda" if torch.cuda.is_available() else "cpu") loader = DataLoader( dataset=Dataset( data="cross-encoder/ettin-reranker-v1-data", tokenizer=tokenizer, max_length=8192, ), batch_size=32, shuffle=True, ) model.train() for epoch in range(5): train_loss = train(model, device, loader) print(f"Epoch {epoch+1}, Train Loss: {train_loss:.4f}") ``` **Conclusion**
The Ettin Reranker family is a new family of efficient rerankers that achieve state-of-the-art results on the MTEB(eng, v2) Retrieval benchmark. These models are built on top of the Ettin ModernBERT encoders and use a combination of attention and feed-forward networks to process input sequences.
We hope this article has provided you with a good understanding of the Ettin Reranker family and how to use them in your retrieve-then-rerank pipelines.