The technology industry has witnessed the emergence of SyGra, a unified framework designed to simplify dataset creation, transformation, and alignment for Large Language Models (LLMs) and Small Language Models (SLMs). This innovative solution aims to address the challenges associated with building high-quality datasets for AI models.
What Happened
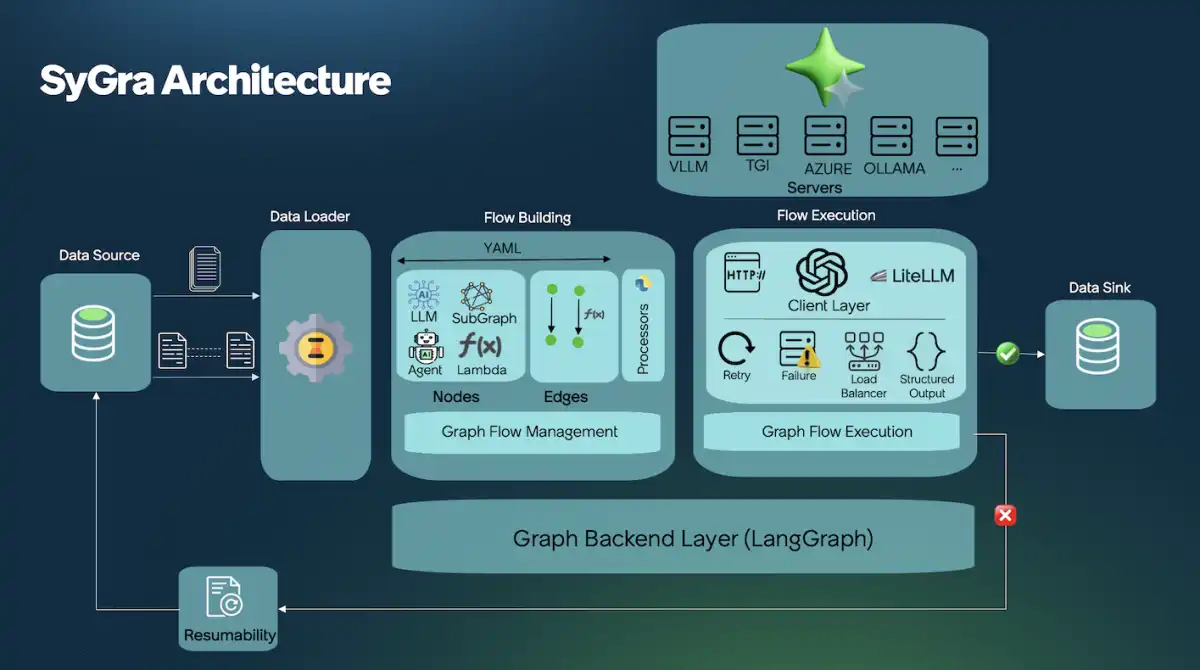
SyGra is a low-code/no-code framework developed by ServiceNow-AI, a team of experts in artificial intelligence. The framework is designed to facilitate scalable and configurable generation of synthetic data tailored for training paradigms such as Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). SyGra employs a modular and configuration-based pipeline that can model complex dialogue flows with minimal manual intervention.
The framework uses a dual-stage quality tagging mechanism, combining heuristic rules and LLM-based evaluations to automatically filter and score data extracted from OASST-formatted conversations. This ensures the curation of high-quality dialogue samples, which are then structured under a flexible schema for seamless integration into diverse training workflows.
Background and Context
The rapid progress of large language models (LLMs) has heightened the demand for large-scale, high-quality training and evaluation datasets. However, the cost, bias, and limited availability of annotated real-world data present significant barriers to achieving this goal. Synthetic data generated via LLMs and automated pipelines offers greater flexibility and control than traditional datasets.
However, achieving synthetic data generation at scale poses significant challenges, including designing complex workflows that mirror task hierarchies, orchestrating diverse model backends, APIs, and tool calls, enforcing validation and schema compliance across large outputs, and enabling resumability, sharding, and streaming for scalable execution. SyGra addresses these challenges by providing a unified framework that empowers users to generate, filter, and align data for their models.
Why it Matters
SyGra matters because data is the foundation of AI, and the quality, diversity, and structure of your data often matter more than model architecture tweaks. By enabling flexible and scalable dataset creation, SyGra helps teams accelerate model alignment, save engineering time with plug-and-play workflows, improve model robustness across complex tasks, and reduce manual dataset curation effort.
The framework's ability to generate high-quality datasets tailored for specific training paradigms makes it an attractive solution for industries that rely heavily on AI models. SyGra's scalability and configurability also make it an ideal choice for large-scale data generation projects.
What Comes Next
SyGra is now available as a Python library, making it easy to integrate into existing ML workflows. The framework supports multiple inference backends, including vLLM, Hugging Face TGI, Triton, Ollama, and more. SyGra's documentation and code are available on GitHub, providing users with a comprehensive resource for learning and implementing the framework.
Key Facts
- SyGra is a unified framework designed to simplify dataset creation, transformation, and alignment for LLMs and SLMs.
- The framework employs a modular and configuration-based pipeline that can model complex dialogue flows with minimal manual intervention.
- SyGra uses a dual-stage quality tagging mechanism to automatically filter and score data extracted from OASST-formatted conversations.
- The framework supports multiple inference backends, including vLLM, Hugging Face TGI, Triton, Ollama, and more.
- SyGra is available as a Python library, making it easy to integrate into existing ML workflows.