The Open ASR Leaderboard has introduced a new feature called the "Benchmaxxer Repellant" to combat benchmark overfitting in automatic speech recognition (ASR) models. This innovation is designed to prevent models from optimizing for specific public datasets rather than demonstrating genuine real-world robustness.
What Happened
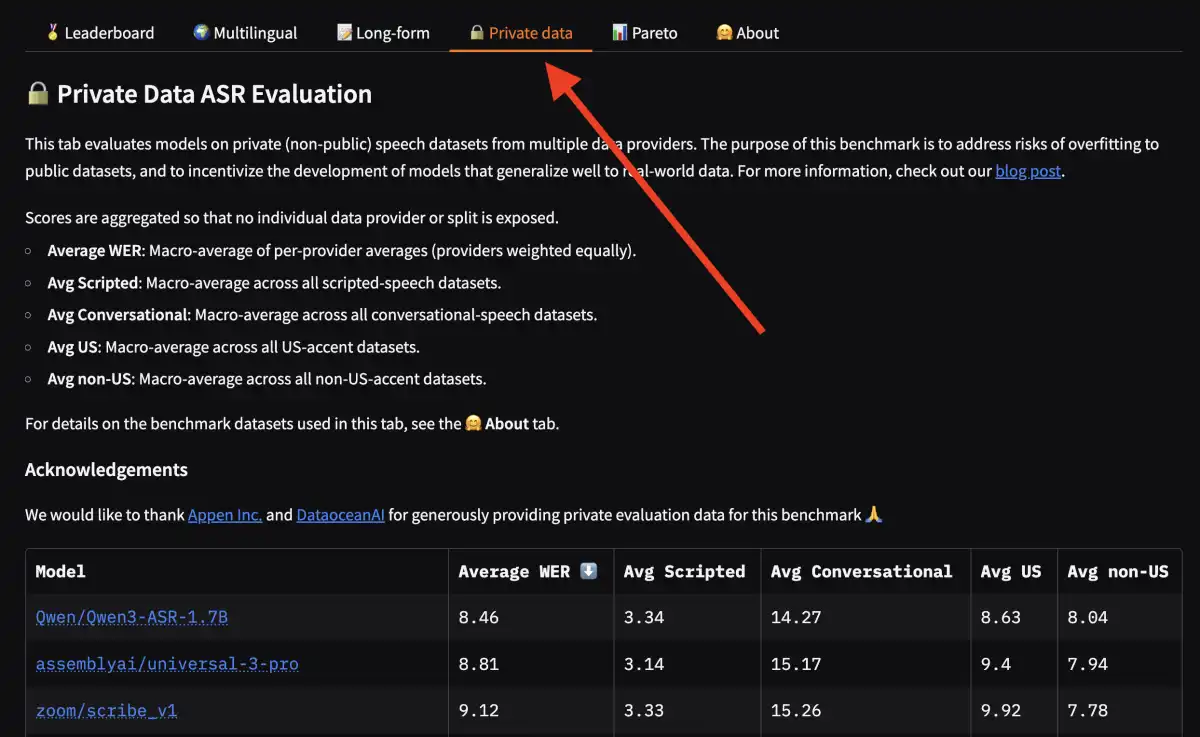
The Open ASR Leaderboard, a benchmarking platform that standardizes evaluation protocols for ASR across diverse datasets and languages, has partnered with Appen Inc. and DataoceanAI to add private evaluation tracks to its leaderboard. These private datasets are kept off-limits from model developers to provide a cleaner signal on real-world performance.
The new feature is designed to address the "benchmaxxer" phenomenon, where models are meticulously tuned to perform exceptionally well on specific public benchmarks but may not generalize well to other scenarios. By incorporating private datasets, the leaderboard aims to evaluate models against undisclosed data, forcing them to demonstrate genuine robustness rather than exploiting public training data anomalies.
Background and Context
The Open ASR Leaderboard has been visited over 710K times since its launch in September 2023. However, as the platform's visibility increased, so did the strategies for gaming leaderboards. Models began to be trained on public test sets, curating data that mirrors known evaluation distributions, and optimizing for macroaverages rather than generalization.
Appen Inc. and DataoceanAI have contributed seven English ASR evaluation sets covering scripted read speech and spontaneous conversational speech across four regional accents. These datasets are designed to measure genuine capability across accent diversity and speech styles.
Why it Matters
The introduction of the "Benchmaxxer Repellant" is a significant development in the ASR community, as it addresses the issue of benchmark overfitting. By evaluating models against private datasets, the leaderboard aims to provide a more accurate representation of real-world performance.
This innovation has implications for the adult industry, where ASR models are used for various applications such as chatbots and voice assistants. The ability to evaluate models against undisclosed data will help developers create more robust and generalizable models that can handle diverse scenarios.
What Comes Next
The Open ASR Leaderboard is planning to continue incorporating high-quality datasets and new evaluation settings to better reflect real-world performance and improve robustness against benchmark-specific optimization. The community is encouraged to provide feedback on the new feature and suggest improvements.
Key Facts
- The Open ASR Leaderboard has introduced a new feature called the "Benchmaxxer Repellant" to combat benchmark overfitting in ASR models.
- The leaderboard has partnered with Appen Inc. and DataoceanAI to add private evaluation tracks to its leaderboard.
- The private datasets are kept off-limits from model developers to provide a cleaner signal on real-world performance.
- Appen Inc. and DataoceanAI have contributed seven English ASR evaluation sets covering scripted read speech and spontaneous conversational speech across four regional accents.
- The leaderboard aims to evaluate models against undisclosed data, forcing them to demonstrate genuine robustness rather than exploiting public training data anomalies.