NVIDIA has released Nemotron 3 Nano 30B A3B, a compact yet powerful reasoning model that achieves better accuracy than its predecessor while activating less than half of the parameters per forward pass. The company has also published an open evaluation standard using NeMo Evaluator, a library designed for robust, reproducible, and scalable evaluation of generative models.
What Happened
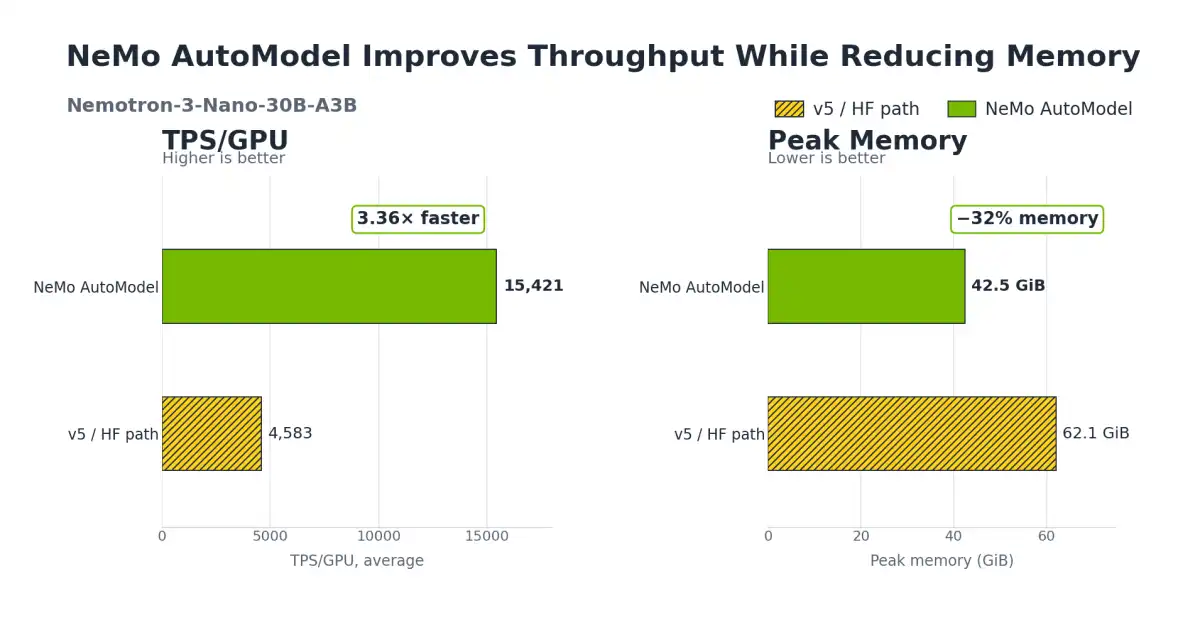
Nemotron 3 Nano 30B A3B is a Mixture-of-Experts hybrid Mamba-Transformer language model that was pre-trained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2. The model was then fine-tuned and trained using large-scale reinforcement learning (RL) on diverse environments. According to NVIDIA's research paper, Nemotron 3 Nano achieves better accuracy than its predecessor while activating less than half of the parameters per forward pass.
The open evaluation standard published by NVIDIA uses NeMo Evaluator, a library designed for robust, reproducible, and scalable evaluation of generative models. The library provides a unified way to define benchmarks, prompts, configuration, and runtime behavior once, then reuse that methodology across models and releases. This approach avoids the common scenario where the evaluation setup quietly changes between runs, making comparisons over time difficult or misleading.
Background and Context
NVIDIA's Nemotron series of language models has been gaining attention in recent years due to its impressive performance on various benchmarks. The previous generation, Nemotron 2 Nano, was a significant improvement over its predecessor, but it still had limitations in terms of accuracy and inference throughput. Nemotron 3 Nano addresses these limitations by introducing a Mixture-of-Experts (MoE) architecture that scales model parameters sparsely.
The MoE architecture used in Nemotron 3 Nano is based on the granular MoE architecture proposed by Dai et al. (2024). This architecture uses a learnt MLP router to activate a subset of experts, reducing the number of parameters activated per forward pass. The result is a significant improvement in inference throughput while maintaining or even improving accuracy.
Why it Matters
The release of Nemotron 3 Nano and the open evaluation standard using NeMo Evaluator has significant implications for the industry. Firstly, it provides a more accurate and efficient language model that can be used for various applications such as chatbots, virtual assistants, and content generation. Secondly, the open evaluation standard ensures that models are evaluated consistently and reproducibly, making it easier to compare models across different environments and releases.
The use of NeMo Evaluator also provides a unified way to define benchmarks, prompts, configuration, and runtime behavior once, then reuse that methodology across models and releases. This approach avoids the common scenario where the evaluation setup quietly changes between runs, making comparisons over time difficult or misleading.
What Comes Next
The release of Nemotron 3 Nano and the open evaluation standard using NeMo Evaluator marks an important milestone in the development of language models. As the industry continues to evolve, it is likely that we will see more advanced models and evaluation methods emerge. The use of MoE architecture and the open evaluation standard provides a solid foundation for future research and development.
Key Facts
- Nemotron 3 Nano 30B A3B is a compact yet powerful reasoning model that achieves better accuracy than its predecessor while activating less than half of the parameters per forward pass.
- The model was pre-trained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2.
- Nemotron 3 Nano uses a Mixture-of-Experts (MoE) architecture that scales model parameters sparsely.
- NeMo Evaluator is an open-source library designed for robust, reproducible, and scalable evaluation of generative models.
- The library provides a unified way to define benchmarks, prompts, configuration, and runtime behavior once, then reuse that methodology across models and releases.
NVIDIA's release of Nemotron 3 Nano and the open evaluation standard using NeMo Evaluator marks an important milestone in the development of language models. As the industry continues to evolve, it is likely that we will see more advanced models and evaluation methods emerge.