An intermittent outage at Cloudflare on Tuesday briefly knocked many of the Internet's top destinations offline, exposing a critical vulnerability in how organizations approach web security and availability. The incident highlighted a dangerous over-reliance on single-vendor solutions and a potential erosion of fundamental security practices.
What Happened
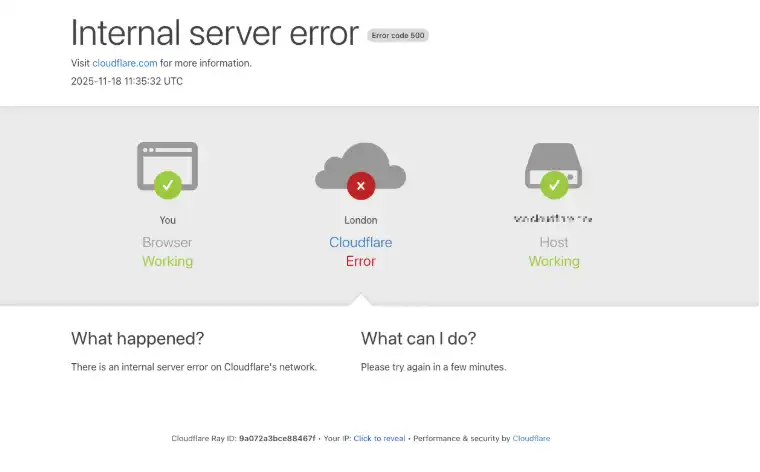
The outage occurred at around 6:30 EST/11:30 UTC on November 18, when Cloudflare's status page acknowledged the company was experiencing "an internal service degradation." After several hours of Cloudflare services coming back up and failing again, many websites behind Cloudflare found they could not migrate away from using the company's services because the Cloudflare portal was unreachable and/or because they also were getting their domain name system (DNS) services from Cloudflare.
However, some customers did manage to pivot their domains away from Cloudflare during the outage. And many of those organizations probably need to take a closer look at their web application firewall (WAF) logs during that time, said Aaron Turner, a faculty member at IANS Research. Turner noted that Cloudflare's WAF does a good job filtering out malicious traffic that matches any one of the top ten types of application-layer attacks, including credential stuffing, cross-site scripting, SQL injection, bot attacks and API abuse.
Background and Context
Cloudflare is a content delivery network (CDN) that offers DDoS protection, web application firewalls (WAFs), and performance enhancements to many businesses. The company estimates that roughly 20 percent of websites use its services, making it a critical component of the modern web infrastructure.
The outage was not caused by a cyberattack or malicious activity, but rather by an internal database issue. Cloudflare CEO Matthew Prince explained in a postmortem published Tuesday evening that the disruption was triggered by a change to one of their database systems' permissions, which caused the database to output multiple entries into a "feature file" used by their Bot Management system.
Why It Matters to the Industry
The Cloudflare outage serves as a stark reminder that relying on single-vendor solutions can be a recipe for disaster. As Turner pointed out, organizations may have become "lazy" in addressing vulnerabilities like SQL injection, assuming Cloudflare's edge protection had them covered. This is a dangerous assumption, and the temporary removal of that protective layer during the outage likely triggered a surge in malicious activity.
The incident underscores a critical point: web application security isn't a set-it-and-forget-it proposition. It requires continuous monitoring, proactive vulnerability management, and a layered defense strategy. Organizations need to understand their exposure *without* the safety net of a CDN. Were your developers truly building secure applications, or were they simply relying on Cloudflare to catch the errors?
What Comes Next
The outage has left many organizations scrambling to review their security practices and assess their reliance on single-vendor solutions. Nicole Scott, senior product marketing manager at Replica Cyber, aptly described the situation as a "free tabletop exercise." The pressure to maintain uptime forced teams to bypass established protocols, potentially leading to the deployment of unsanctioned tools and workarounds – a phenomenon known as shadow IT.
Scott's six key questions for post-outage analysis are crucial:
- What was turned off or bypassed (WAF, bot protections, geo blocks), and for how long?
- What emergency DNS or routing changes were made, and who approved them?
- Did people shift work to personal devices, home Wi-Fi, or unsanctioned Software-as-a-Service providers to get around the outage?
- Did anyone stand up new services, tunnels, or vendor accounts "just for now"?
- Is there a plan to unwind those changes, or are they now permanent workarounds?
- For the next incident, what's the intentional fallback plan, instead of decentralized improvisation?
Key Facts
- The outage occurred at around 6:30 EST/11:30 UTC on November 18.
- Roughly 20 percent of websites use Cloudflare's services.
- The outage was not caused by a cyberattack or malicious activity, but rather by an internal database issue.
- Cloudflare CEO Matthew Prince explained that the disruption was triggered by a change to one of their database systems' permissions.
- Aaron Turner noted that Cloudflare's WAF does a good job filtering out malicious traffic that matches any one of the top ten types of application-layer attacks.